It appears that AMD has at least one innovative answer to NVIDIA’s upcoming multi-chip-module (MCM) Hopper graphics architecture. As spotted by various users on social media, red team has filed a patent for a radical new GPU design that leverages a system comprising chiplets for what could be a massive leap in graphics performance. The technology would presumably be used in the company’s future Radeon RX graphics cards.
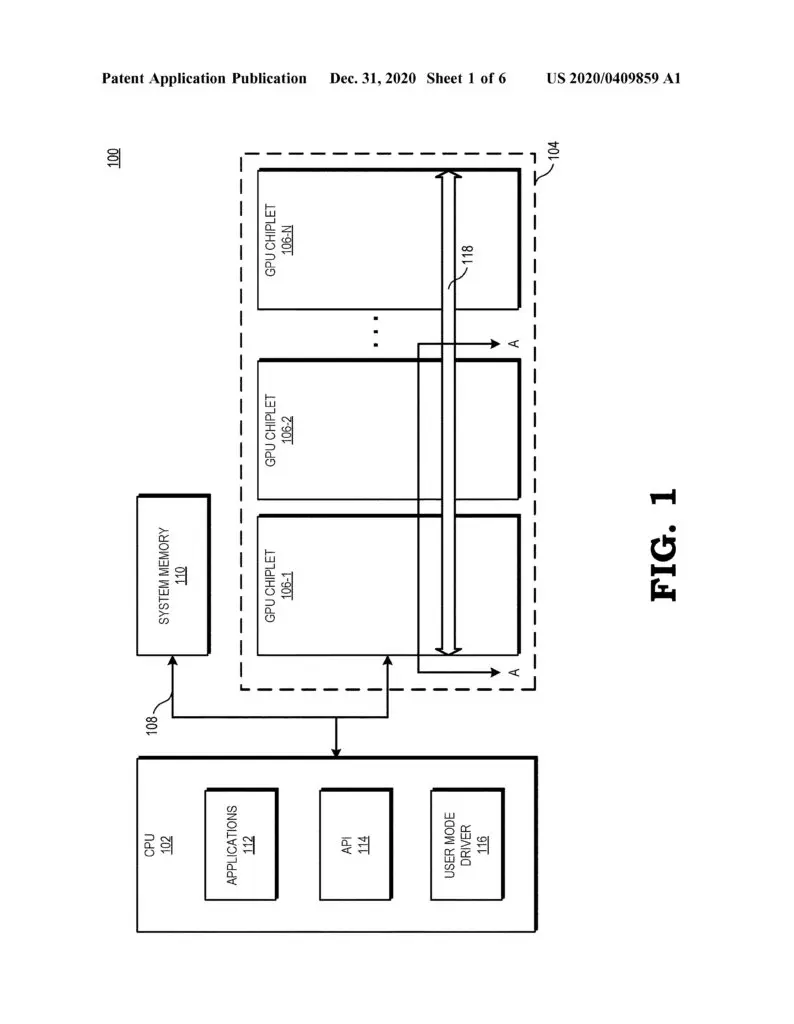
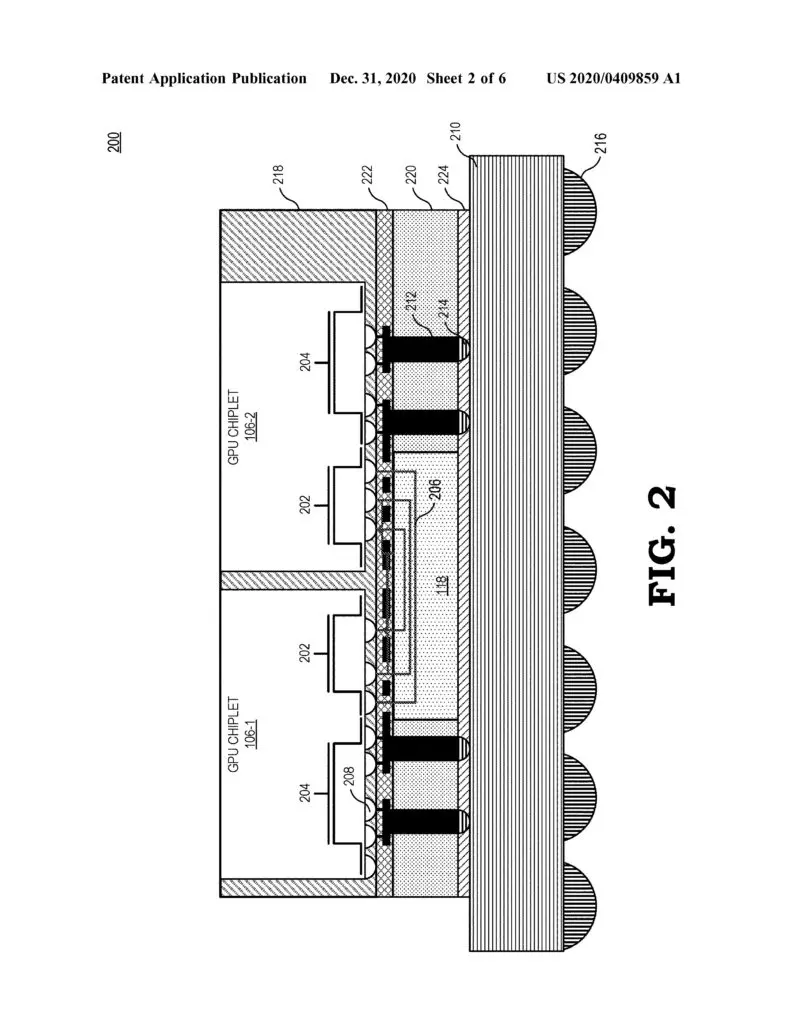
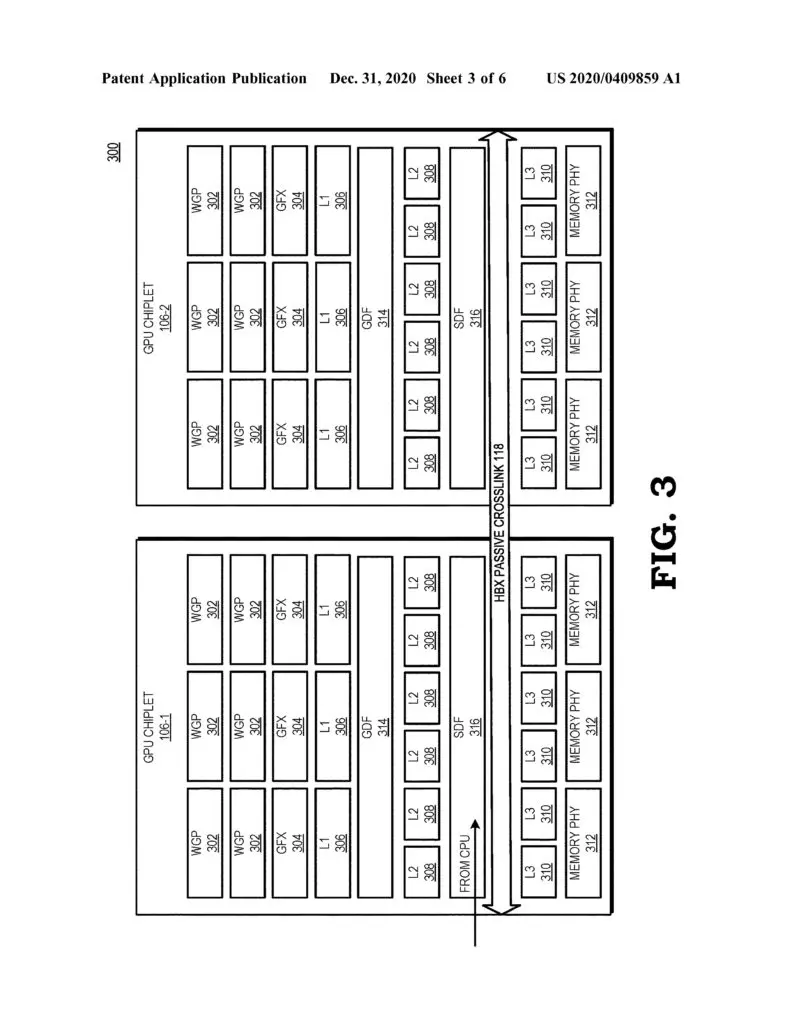
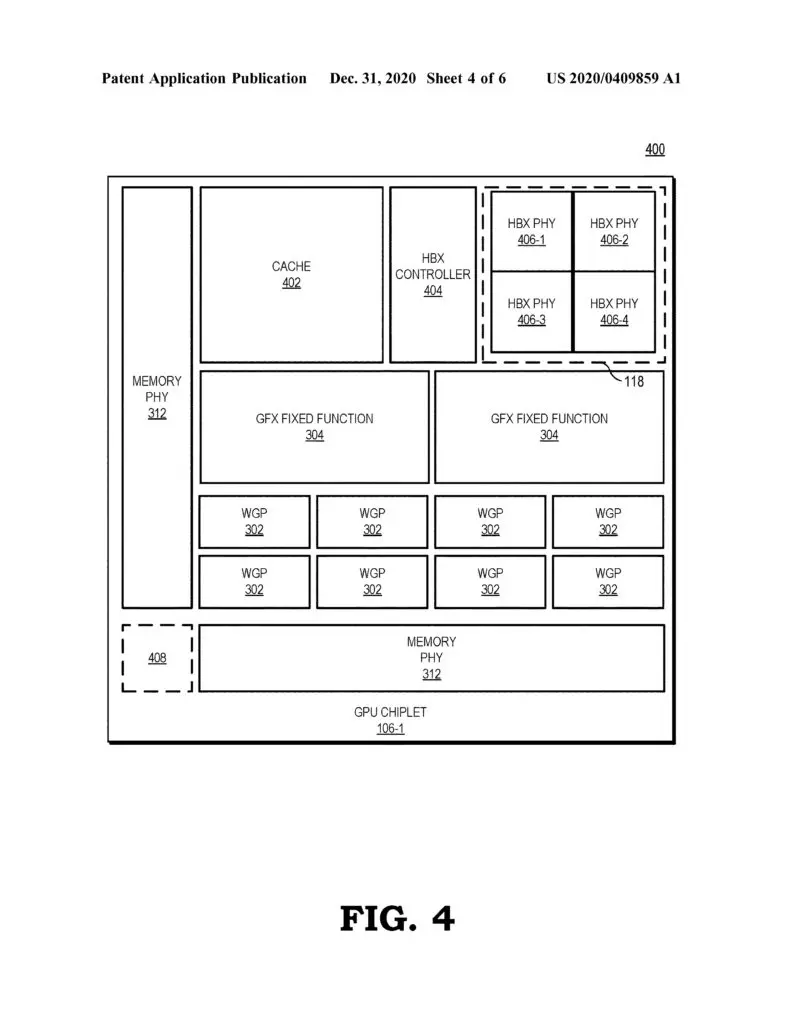
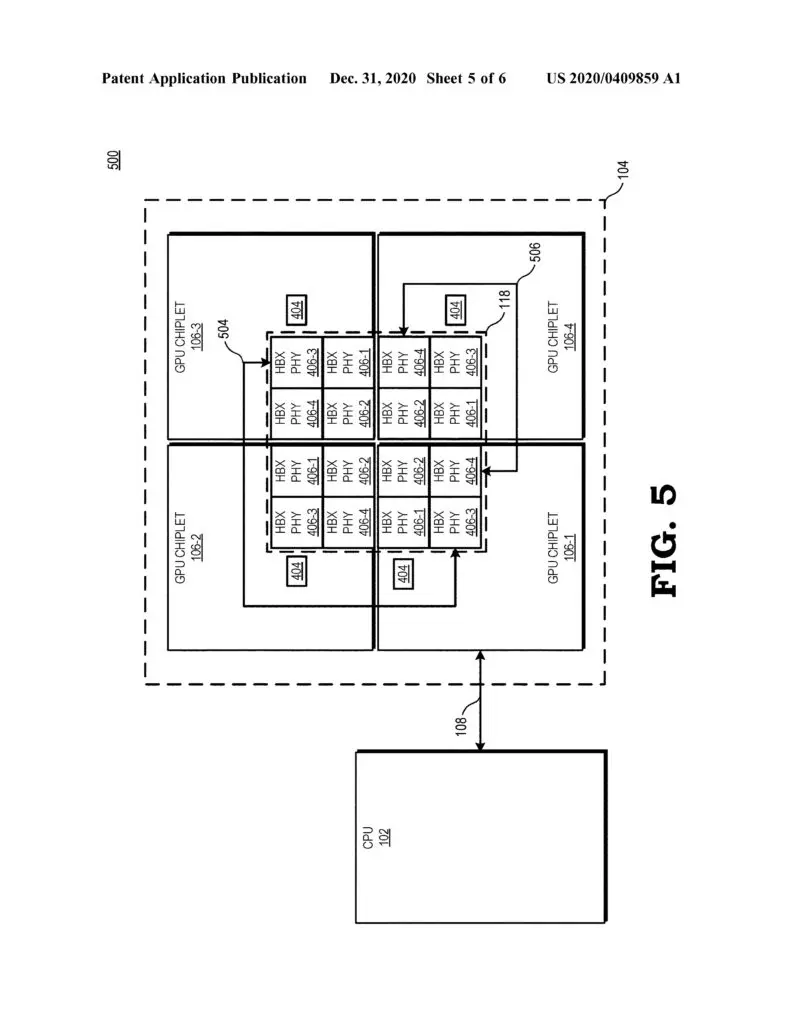
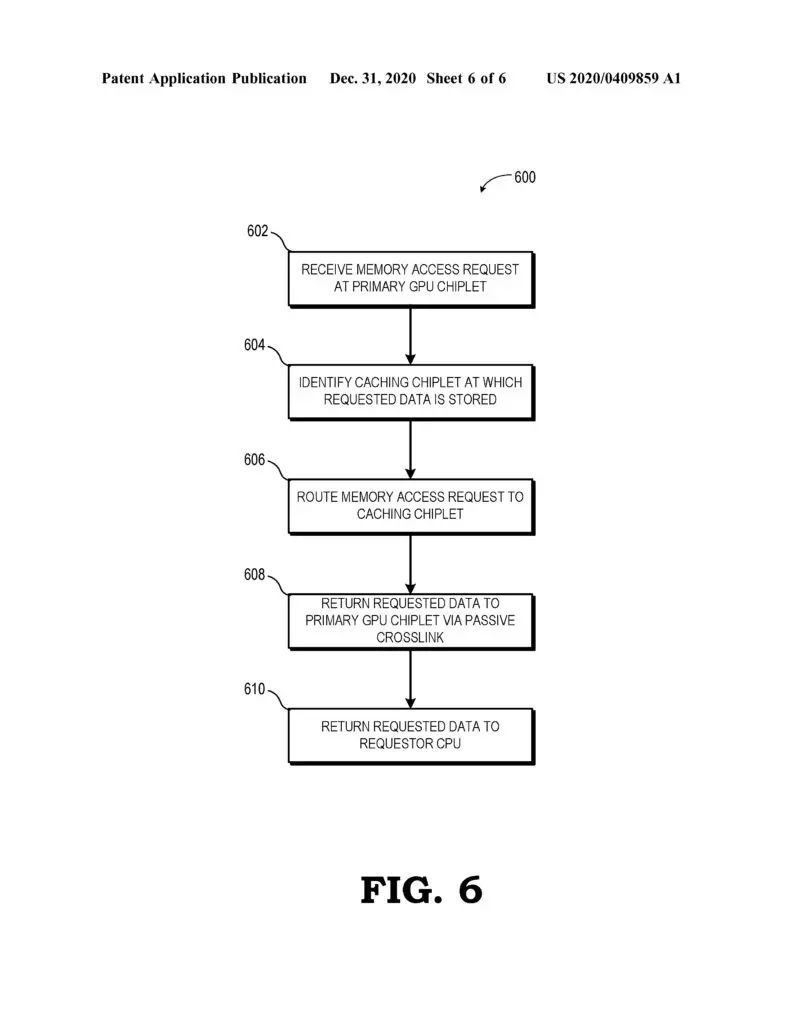
“A chiplet system includes a central processing unit (CPU) communicably coupled to a first GPU chiplet of a GPU chiplet array,” an abstract reads. “The GPU chiplet array includes the first GPU chiplet communicably coupled to the CPU via a bus and a second GPU chiplet communicably coupled to the first GPU chiplet via a passive crosslink. The passive crosslink is a passive interposer die dedicated for inter-chiplet communications and partitions systems-on-a-chip (SoC) functionality into smaller functional chiplet groupings.”
AMD points out that the development of a chiplet GPU has been hindered by various challenges, such as figuring out how to distribute work properly across so many parts using traditional programming models, but the company believes that it may have a solution with the use of high bandwidth passive crosslinks for coupling chiplets.