Process and Package










Integral to Intel Panther Lake is the process and packaging. Notably, Intel will be using its Intel 18A process on the CPU compute tile in the package. There are some key new technologies that will allow more scalability, efficiency improvements, and performance. Intel is now using new transistor technology, leading in fact in this area, with the use of the more advanced RibbonFET technology, which supersedes FinFET. RibbonFET technology allows better gate control of the transistor, which allows the process node to be reduced, and more transistors packed in without leakage.
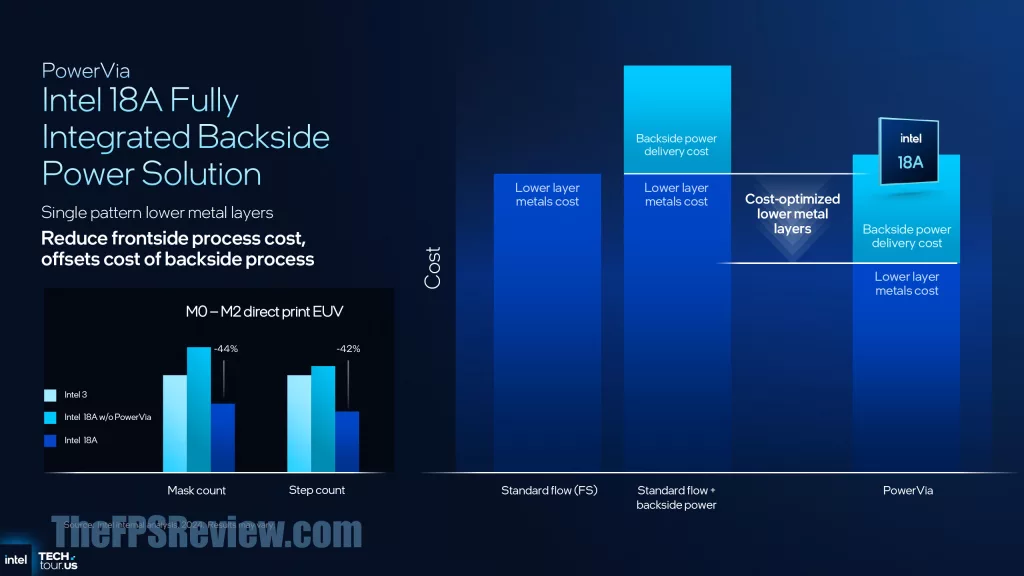
Another very important technology is PowerVia, which essentially adds backside power delivery to the transistors. In doing this, you can achieve a cleaner signal and power for each transistor, which is very important when shrinking the process. Typically, backside power is expensive in cost, but since Intel designed this from the ground up with this in mind, it was able to strip other processes in a traditional frontside design to offset some of the cost in manufacturing. What is the result for the end-user? The potential for performance per Watt increase and the ability to scale up frequency with smaller nodes, or reduced power at the same performance.


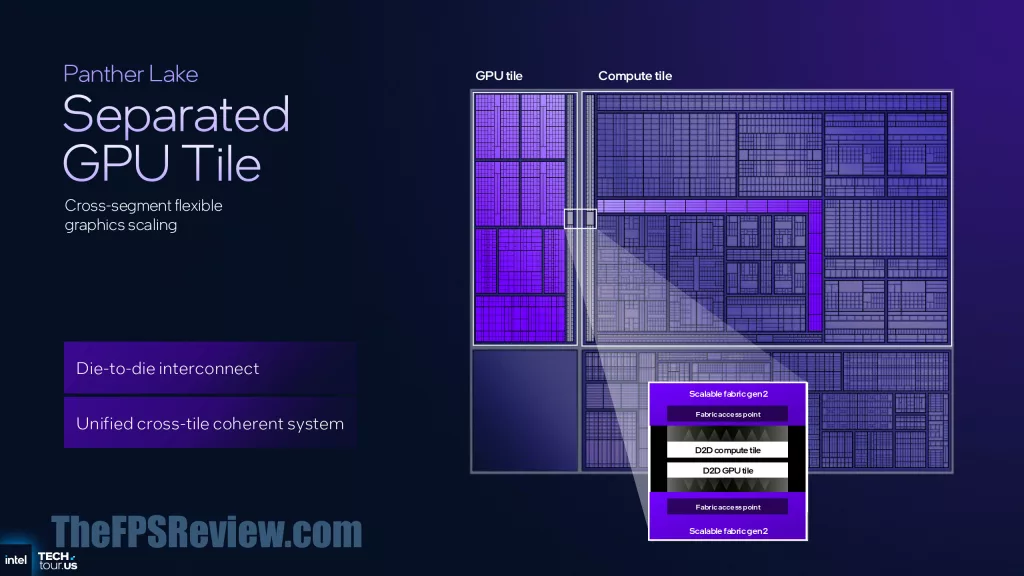



So how is it all put together? Well, in tiles, naturally, something Intel has been working with for a long while now. As you saw above, there is a separate Compute tile, GPU tile, and Platform Controller tile all atop a Base tile. This is connected through the Foveros packaging.
Compute Tile







Let’s move on now, specifically to the Compute tile and the new architectures for the P-Core and E-Cores. Intel Panther Lake does use a new architecture which supersedes Intel Lunar Lake, and is an evolution of that architecture. On Lunar Lake, the P-Core architecture was called Lion Cove, and the E-Cores used Skymont architecture. For Intel Panther Lake, the P-Cores get upgraded to the Cougar Cove architecture, and the E-Cores, both normal power and LP, get upgraded to Darkmont architecture. These architectures are designed to take advantage of Intel 18A using the new transistor technologies discussed previously, and we see the architecture scaled up, and at better efficiency and additional IPC.



The Cougar Cove architecture, which makes up the P-Cores, is an evolution in architecture, with specifics scaled up to improve IPC. The L2 and L3 cache sizes have been increased in Cougar Cove. Cougar Cove increases the L2 cache size to 3MB, which on Lion Cove was 1.5MB for Lunar Lake configurations. In addition, the L3 cache size has been increased to 18MB on Cougar Cove, where it was 12MB on Lion Cove for Lunar Lake. Core optimizations that improve IPC include support for memory disambiguation now, TLB enhancements, and branch prediction. Thread Director also gets an upgrade, which we’ll talk about later.


The Darkmont E-Core architecture, in a similar way, gets bumped up in optimizations for IPC. Branch prediction has been improved with accuracy refinements, memory disambiguation is supported, dynamic prefetcher controls and nanocode performance with more instructions.
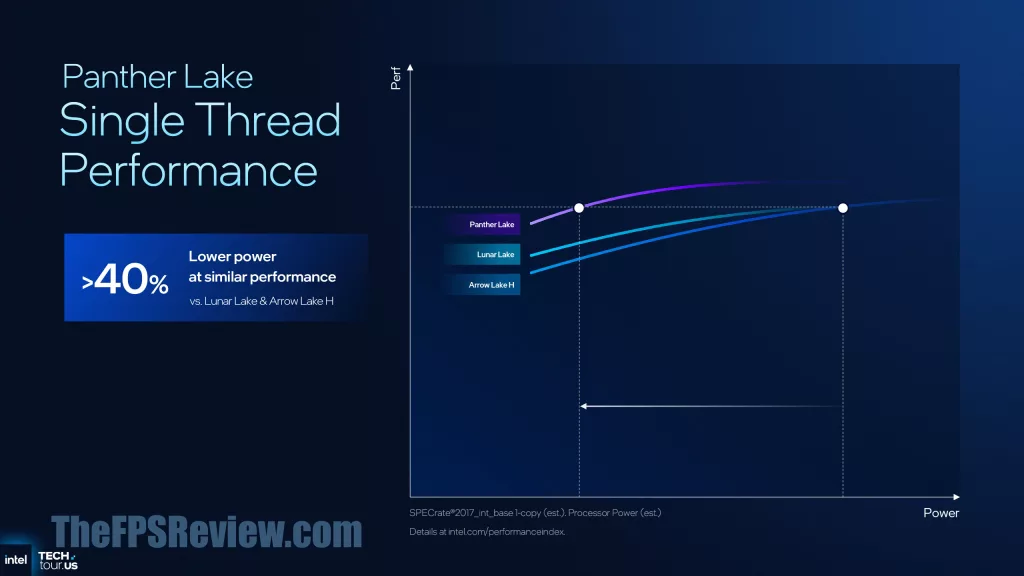
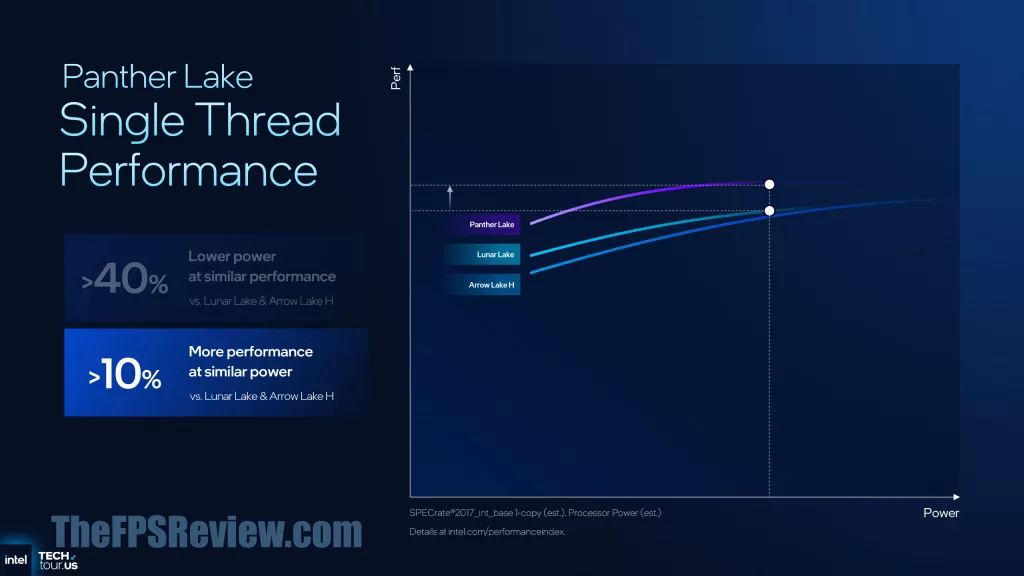
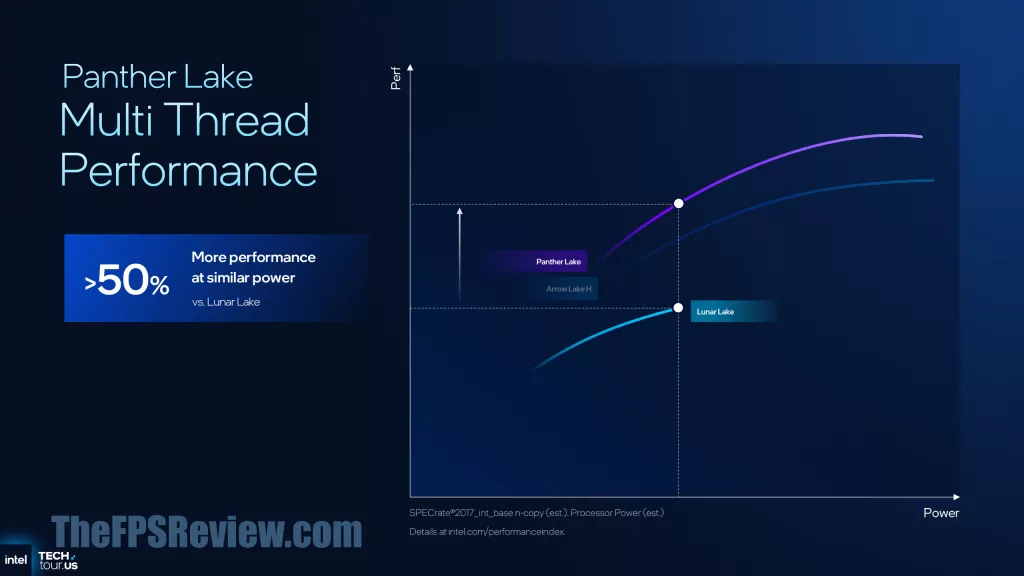
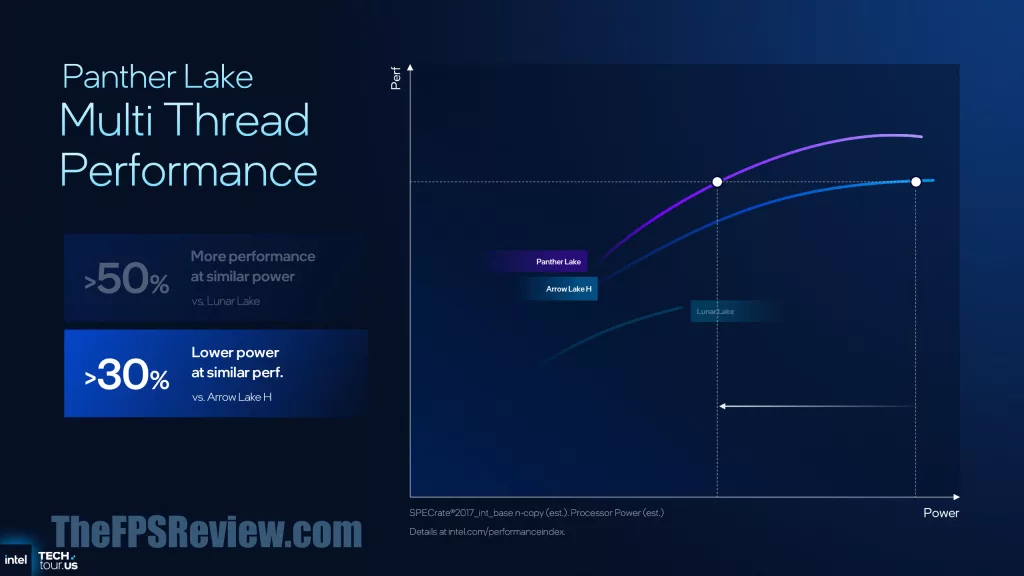
So how does that all boil down to for the end-user, well according to Intel, expect a 10% single-thread performance uplift versus Intel Lunar Lake & Arrow Lake-H at similar power. Or, expect 40% lower power at similar performance, compared to Lunar Lake & Arrow Lake-H. For multi-threading performance, however, Intel is claiming a 50% performance increase at similar power compared to Lunar Lake. This is due to the scaling upwards of cores, which scales linearly. Or, 30% lower power at similar performance to Arrow Lake-H.
Intel Thread Director

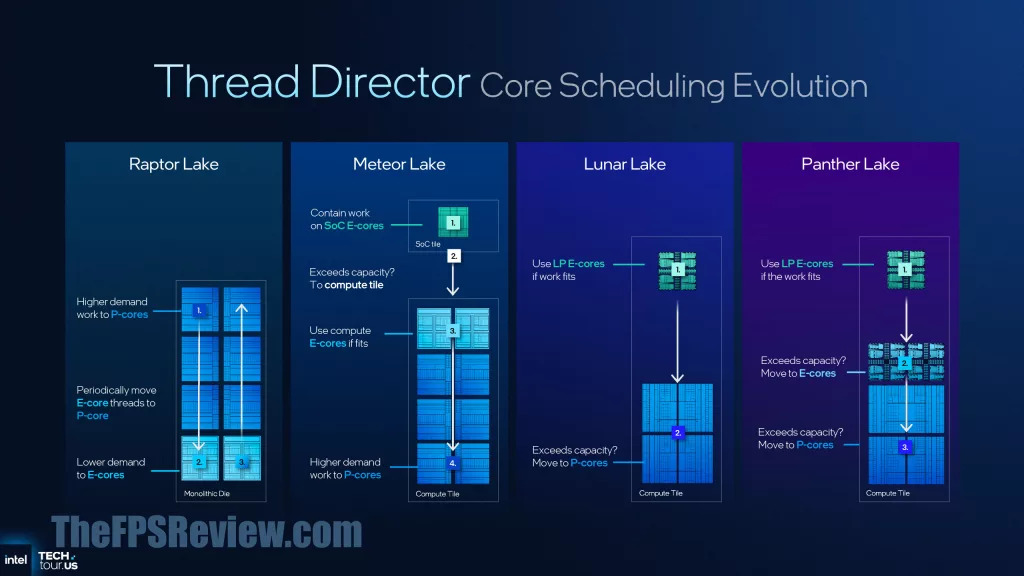

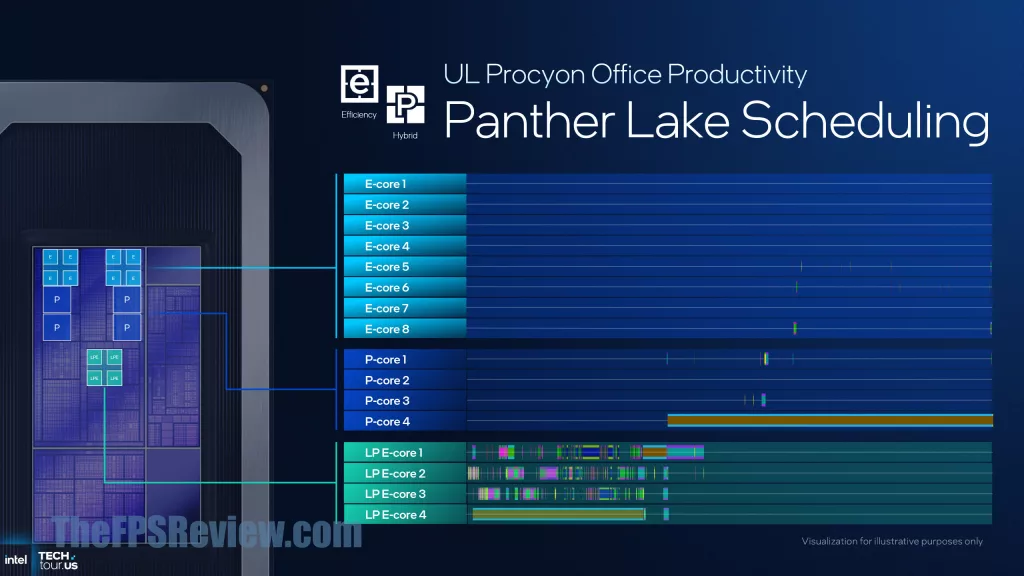

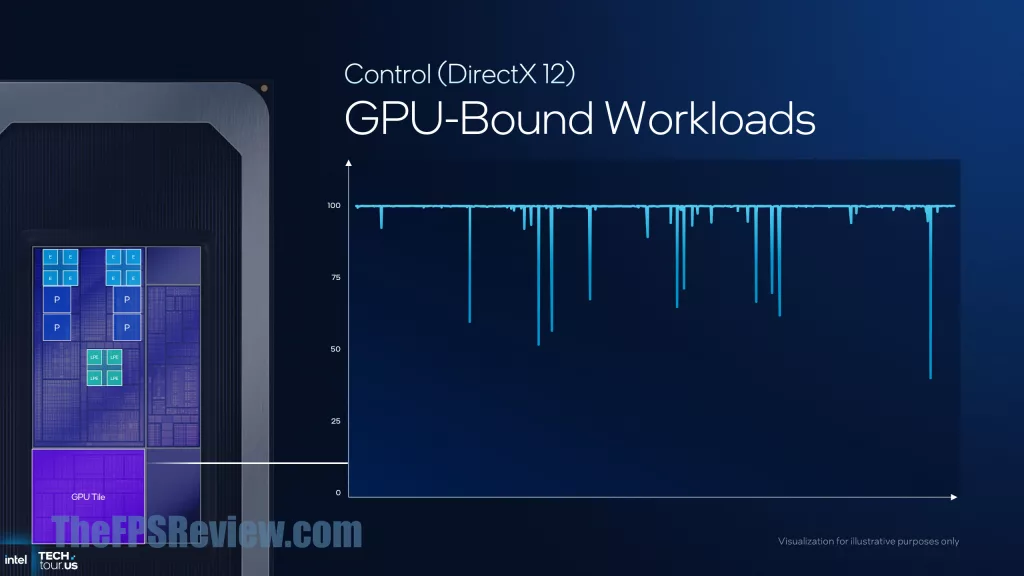


With the change in configuration and architecture, Intel Thread Director needs updating, and so Intel has done that for Panther Lake. The thread guidance has been expanded across a wider set of real-world use cases, and the classification of threads has been updated. There is also more telemetry inputs on the cores to direct Thread Director with information. In Panther Lake, LP E-Cores start the work, but if they need capacity, it then moves to E-Cores, and then to P-Cores. One thing Intel has done this generation is to better optimize for GPU workloads, smoothing out performance and recognizing GPU-bound workloads to prefer P-Cores and E-Cores.
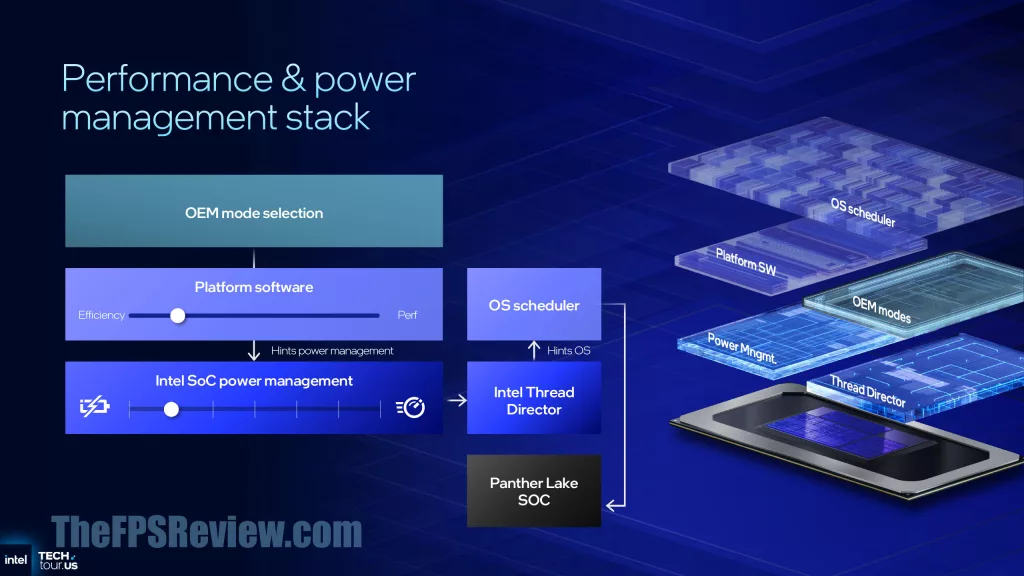

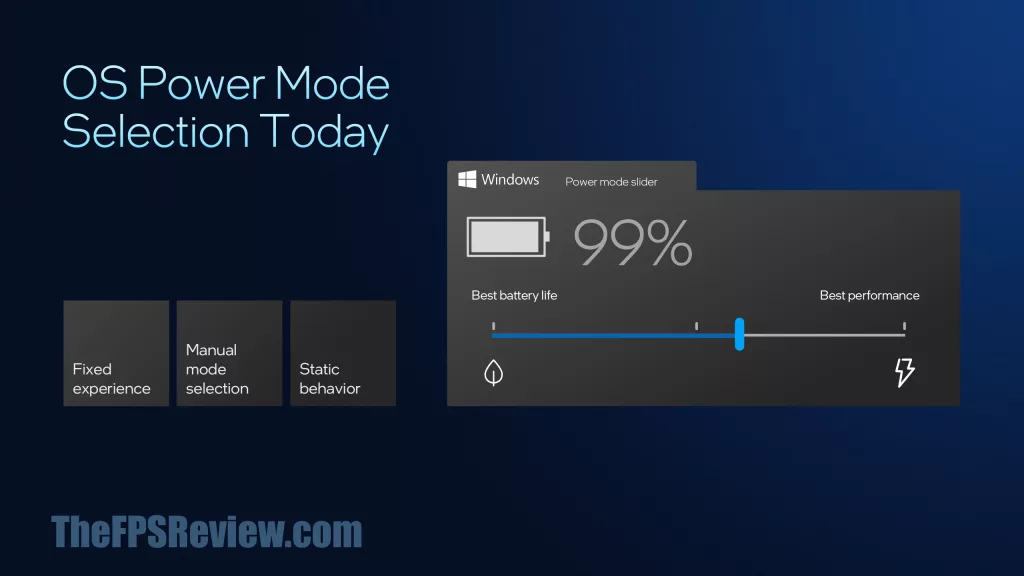
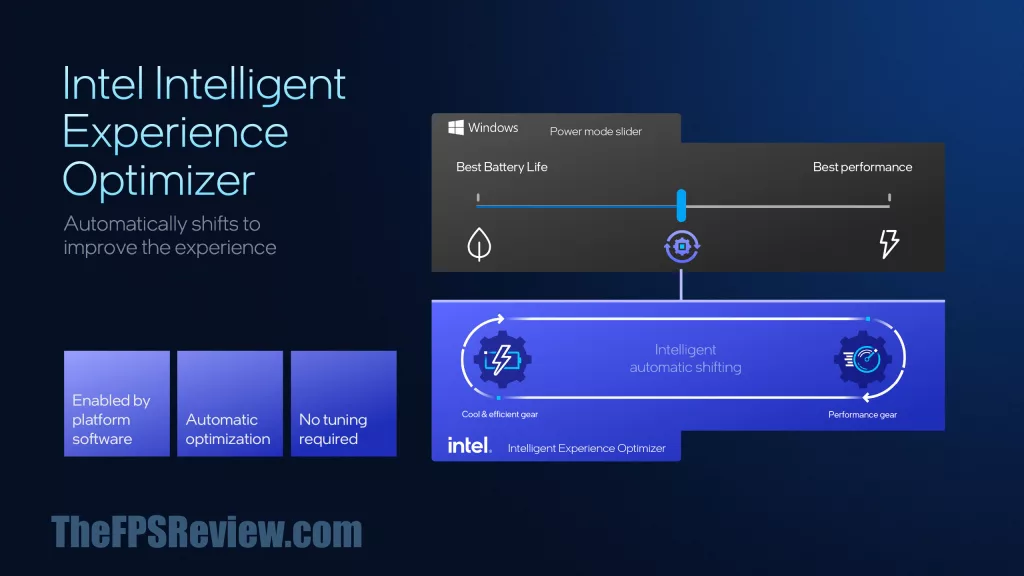

Along with Thread Director is a new mechanism to automatically optimize performance and battery on the fly, without user input. With the Windows power profile set to Balanced, Intel Intelligent Experience Optimizer will automatically, using AI, determine if Best Performance or Better Battery Life is needed in real-time. This means you will no longer have to manually select better performance or better battery; with this optimizer, it is done intelligently and automatically. It’s an interesting concept, so we’ll have to see how that works out in the real world.