
Introduction
The successor to NVIDIA’s Turing architecture and the replacement for the GeForce RTX 2000 series is finally here. That said, if you are coming from an older generation such as Pascal (GeForce 10 Series), CEO Jensen Huang made it clear in his Official Launch Event for the NVIDIA GeForce RTX 30 Series that you now have permission to upgrade, this is the one you are looking for, it’s safe. Here is the official press release. Here is the long official information page from NVIDIA with all the goodies about this launch.
It is finally time to replace your GeForce GTX 1060, or 1070, or 1080 or even 1080 Ti. These RTX 30 series cards upgrade is a much bigger upgrade than what the Turing generation, GeForce RTX 2000 series brought to standard, rasterized, gameplay performance. For those currently on the Turing architecture (GeForce RTX 2000 series) the new Ampere GPUs promise to bring much improved and finally useful levels of performance with NVIDIA RTX features like Ray Tracing and DLSS.
On the bench today we have the brand-new NVIDIA GeForce RTX 3080 Founders Edition video card directly from NVIDIA which has an MSRP of $699. It should be noted, the Founders Edition is a unique design from NVIDIA, it is not the reference design. There is actually a reference design with a rectangular PCB that all add-in-board partners will have. Before we go into card details and specifications, let’s take a little look at the Ampere architecture that the GeForce RTX 3080 Founders Edition is based on.
Ampere
The new generation of GPUs that are being launched are based on the NVIDIA Ampere architecture. This architecture continues the RTX branding because NVIDIA Ray Tracing and DLSS are two very important features of focus for this generation. In fact, most of the improvements made directly affect Ray Tracing and AI/DLSS functions and floating-point performance.
The Ampere architecture is based on an interesting manufacturing process this generation; NVIDIA has gone to Samsung to create a custom 8nm node with 28 billion transistors. This specific Samsung 8nm node is an enhancement of the Samsung 10nm process branch, it is not on Samsung’s new 7nm EUV process sadly. By comparison, TSMC’s 7nm process and Samsung’s 7nm EUV process is better. This will ultimately affect clock speed capability out of the Samsung 8nm node.
The result of using Samsung 8nm is that these GPUs are going to gobble power and output high thermals to achieve the performance targets. The obtainable clock speeds will not be what they could be on a better process. This is why most likely we see a huge bump in CUDA Cores, to offset the lower GPU clock speeds. If you can’t ramp up the clock speed, then you double down on cores. There is just no getting around this, this fact is proven in the design of the video cards we see today. NVIDIA has cleverly managed the power and temperatures this generation with its very smart engineers and custom Founders Edition design. The proof is the pudding though, so to speak, so let’s see what the performance turns out to be in this review. BTW, we do plan to do overclocking in a separate review.
Shaders



Aside from the node, the architecture itself is very sound. One of the main components of performance is the fact that NVIDIA has designed a new datapath for FP32 and INT32 operations which results in all four partitions combined executing 128 FP32 operations per clock. This doubles the FP32 operations to two shader calculations per clock compared to the prior Turing architecture only executing one FP32 per clock. This is the primary change to the programable shader operations.
The question is, will this still speed up traditional game performance? NVIDIA goes on to say that gaming performance will be sped up because graphics and compute algorithms rely on FP32 executions on modern shader workloads. NVIDIA also states that Ray Tracing denoising shaders benefit from FP32 speedup, the heavier the Ray Tracing the bigger the performance gain versus the last generation. As shader workloads continue to intensify, FP32 will help more.
In the past we’ve seen ATI go down this road, prioritizing floating-point performance over integer and that didn’t work out so well for them at the time. However, it’s a different time now, and maybe games have finally moved into the era where floating-point is more important than ever. We will have to see. It is because of this doubling of the FP32 ops that you will see the CUDA cores be counted in a different way now.
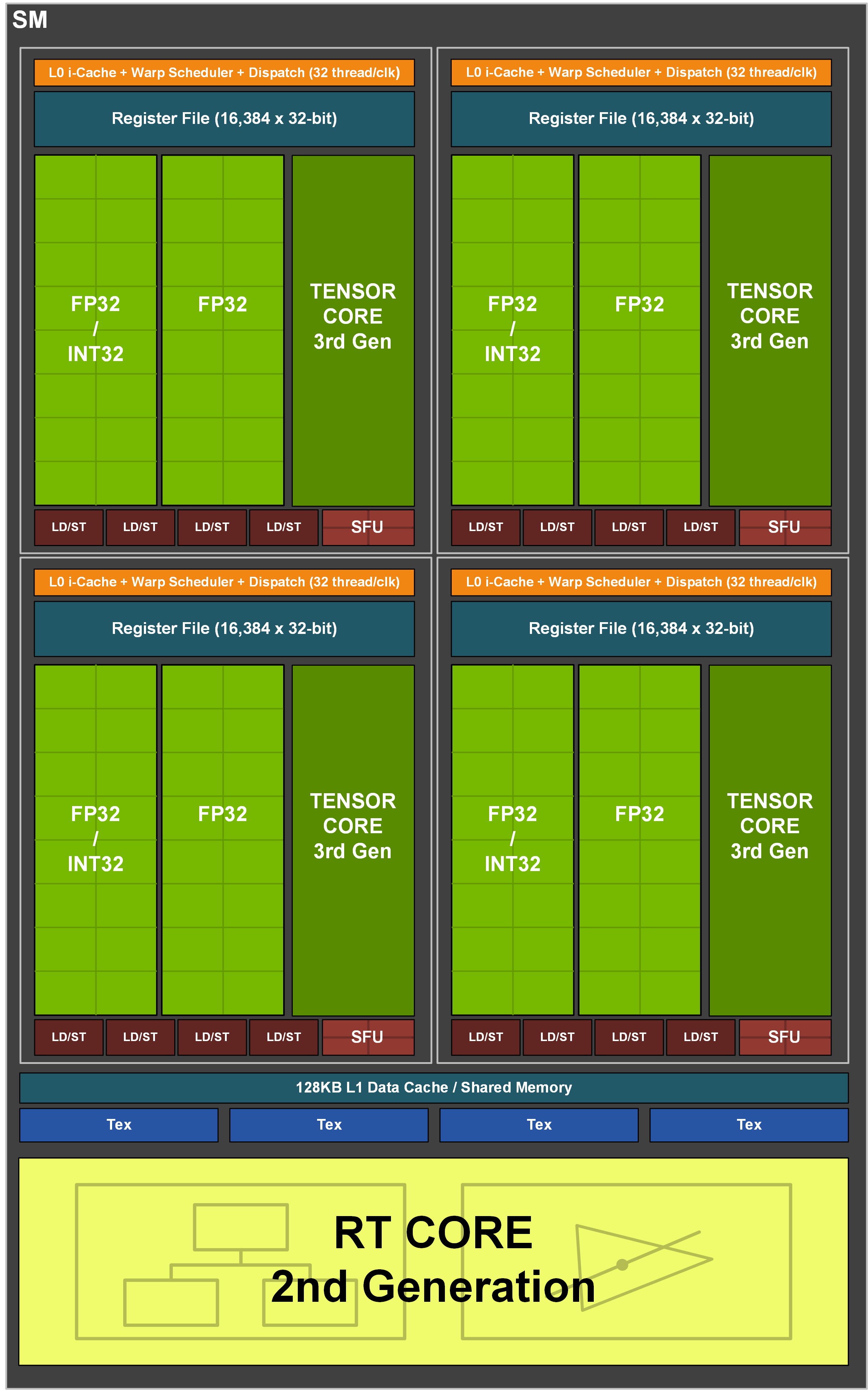
Inside the SM each block has an FP32 and FP32+INT32 and a Tensor Core. The prior generation had just one separate FP32, one separate INT32, and two Tensor Cores. That’s right, Turing had 8 Tensor Cores per SM, and Ampere has 4. BUT, the Tensor Cores have been updated in capability, as we’ll discuss below.
Instead, an FP32 has been added to an INT32 and concurrent execution of floating-point and integer is possible. L2 bandwidth has also been improved and improved to 33% more capacity and 2x the cache partition size.

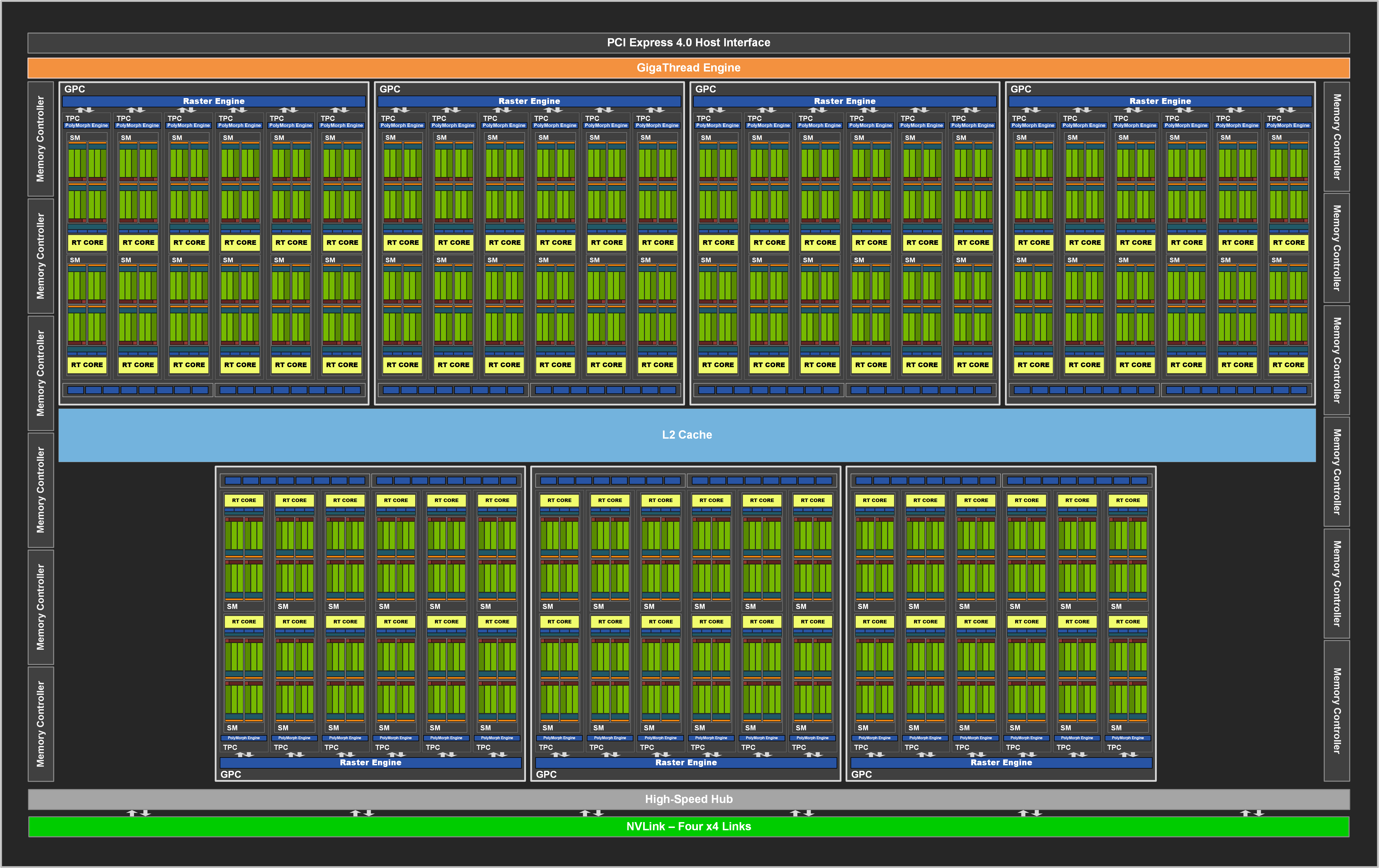
Going by the numbers you can see how GeForce RTX 2080 SUPER GPU block diagram directly compares with GeForce RTX 3080 GPU block diagram.
RT Cores 2nd Generation
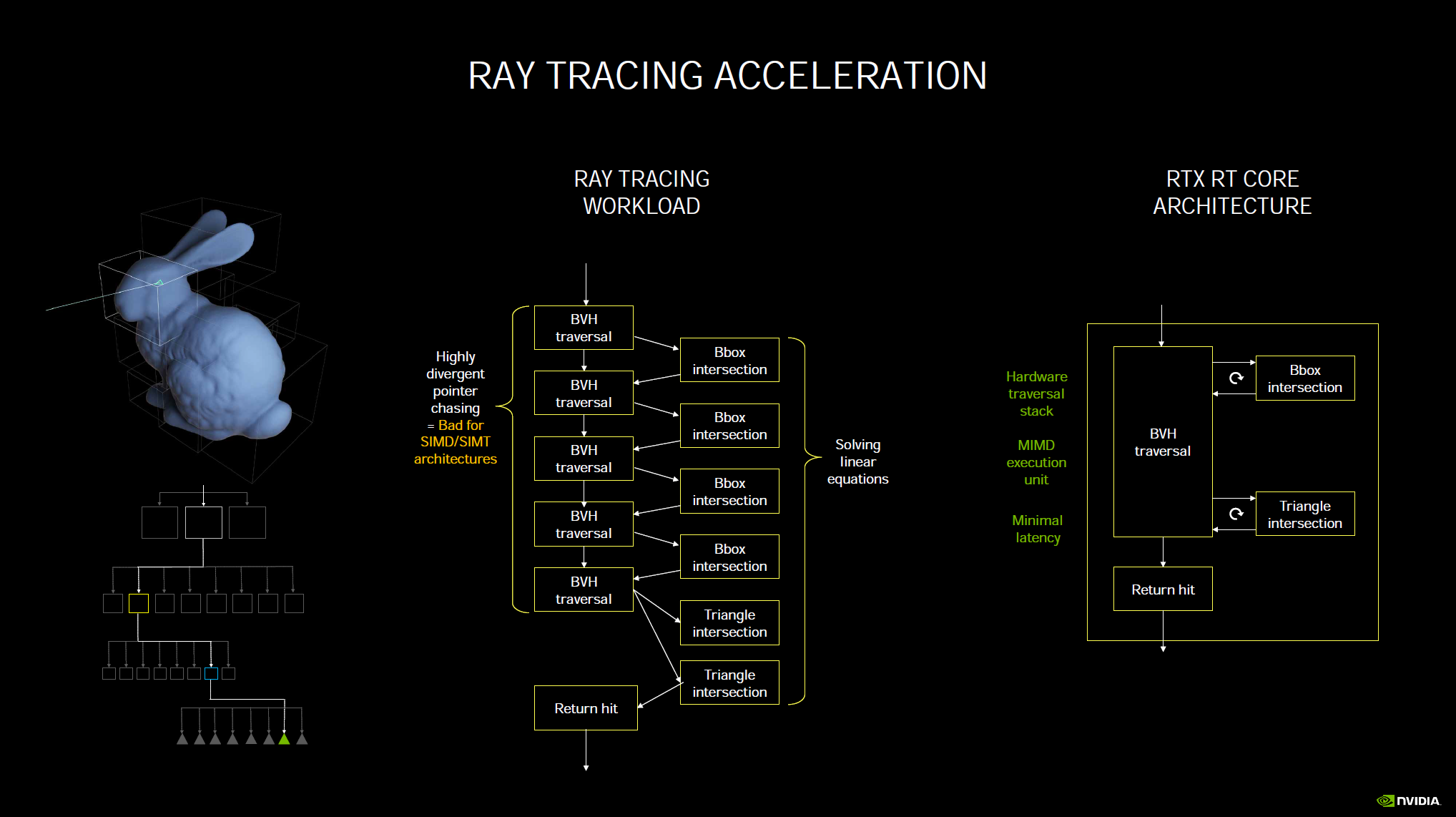

The RT Cores have been beefed up, and it is using NVIDIA’s 2nd generation RT Cores that allow 2x the triangle intersection rates. Where the prior generation RT Cores could do 34 RT TFLOPS the Ampere architecture can do 58 RT TFLOPS. The new RT Cores also allow for concurrent Ray Tracing and shading operations.
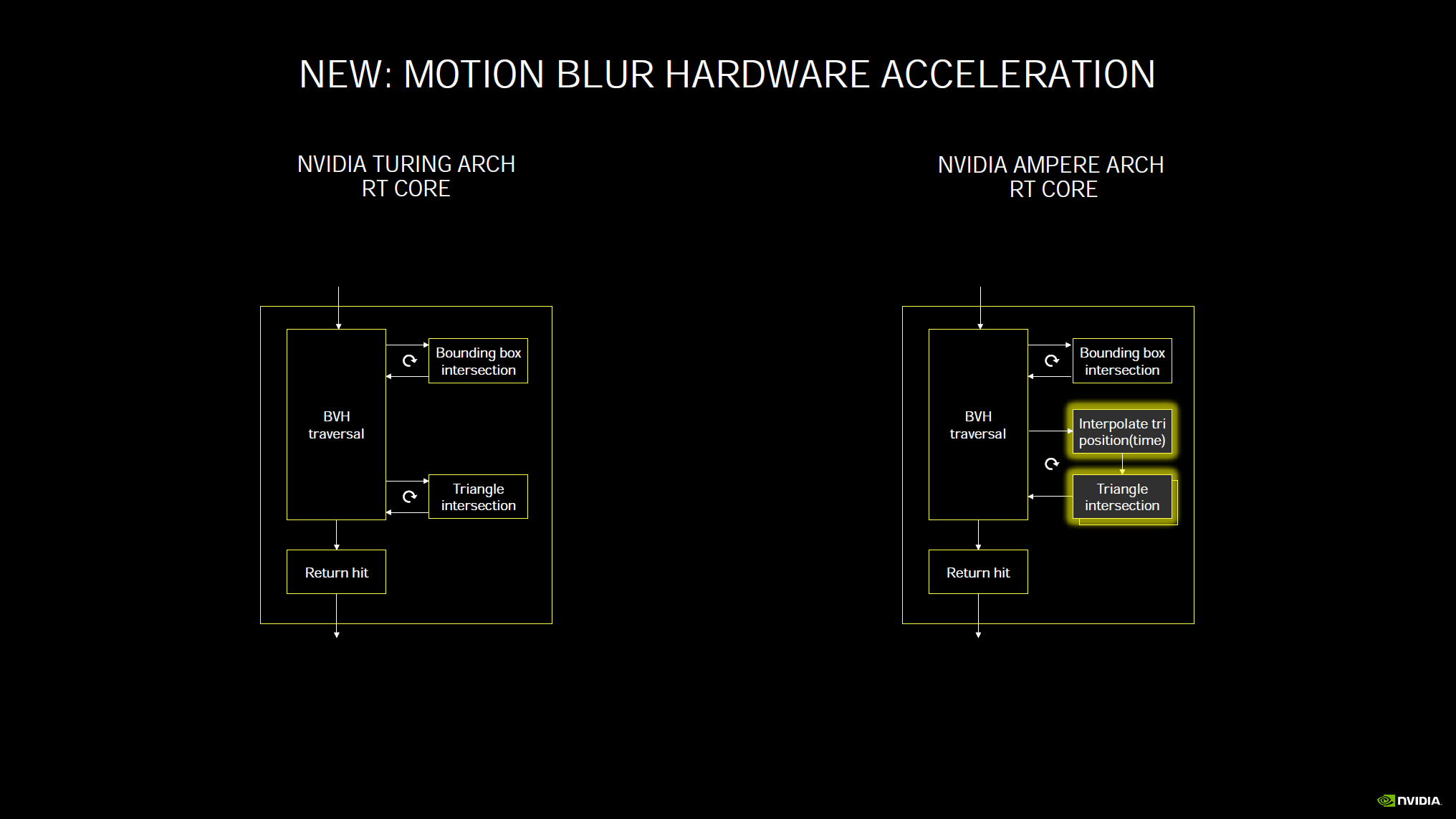
There are also more of them this generation in each video card. With Ampere RT Cores now accelerate Ray Tracing with Motion Blur. The pipeline adds an Interpolate of triangles by position in time, something which the prior generation did not have. The end result is that using Ray Tracing with Motion Blur is now up to 8x faster, motion blur is no longer a bottleneck when used with Ray Tracing.
Tensor Cores 3rd Generation
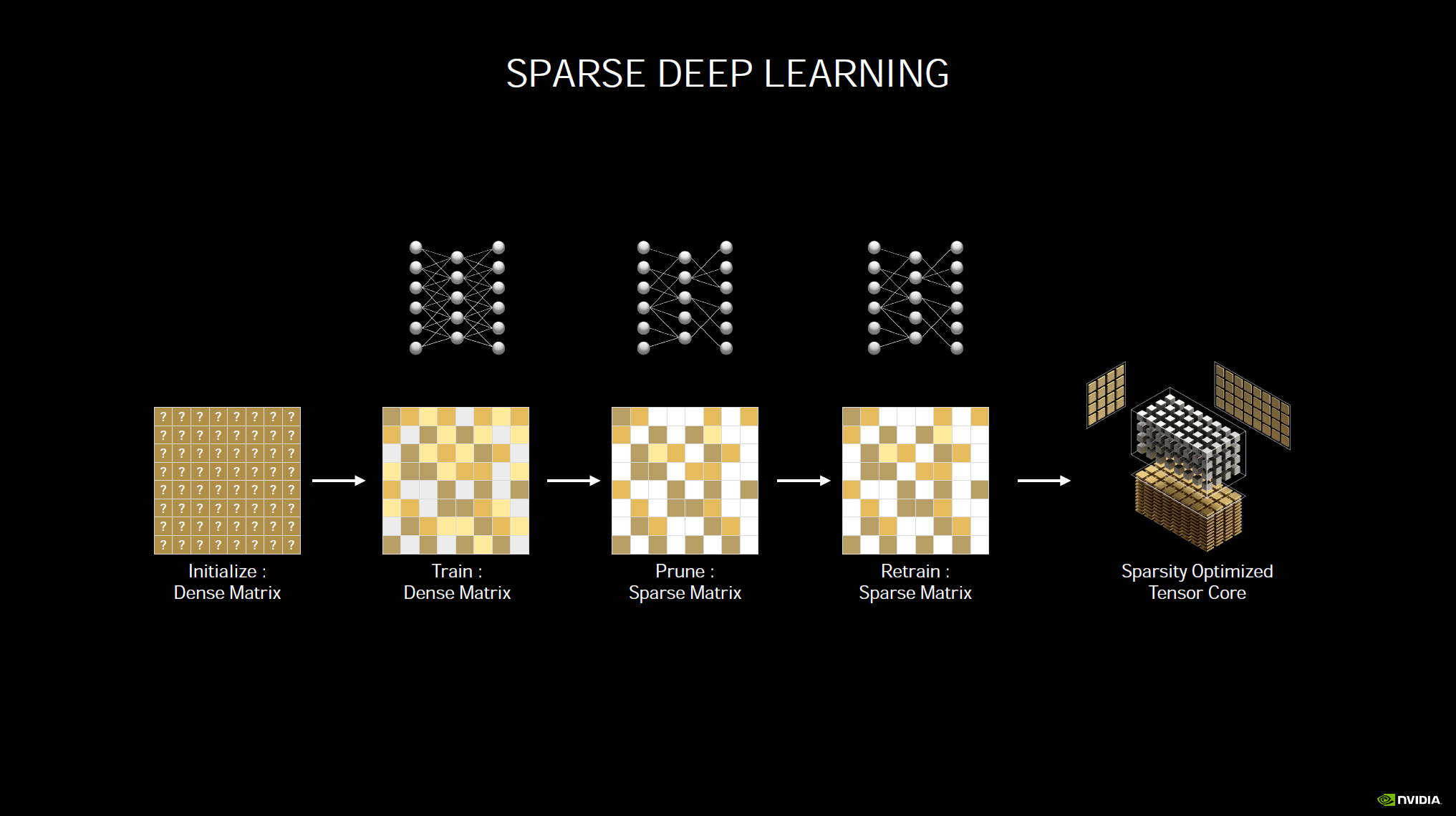
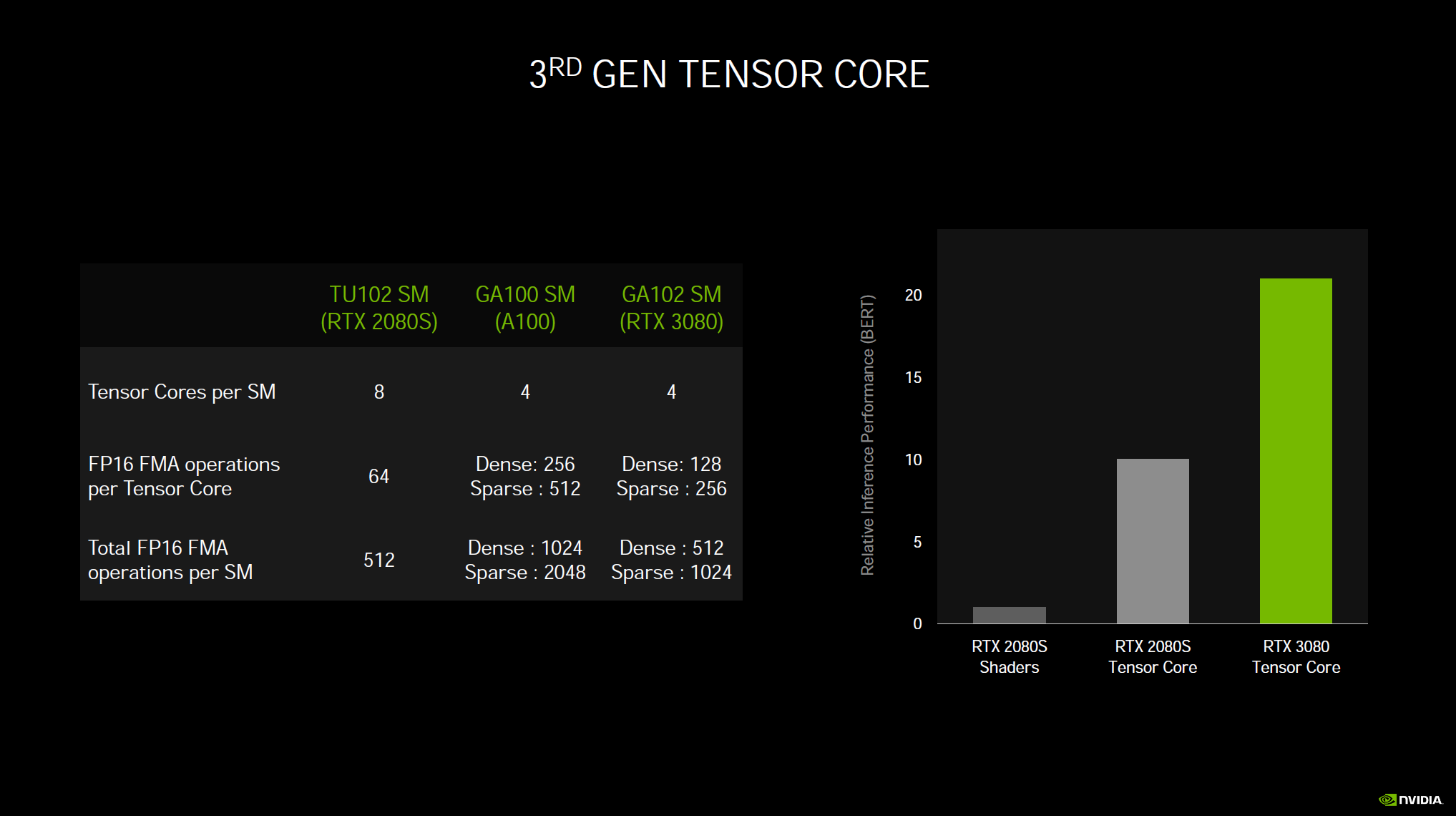
The Tensor Cores have also been beefed up and it is using NVIDIA’s 3rd generation Tensor Cores that allow up to 2x math for sparse matrices. The new Tensor Cores can automatically identify and remove less important DNN weights and the new hardware processes the sparse network at twice the rate of Turing. Where the prior generation Turing architecture could do 89 Tensor TFLOPS Ampere can do 238 Tensor TFLOPS. Tensor Cores are used for DLSS (Deep Learning Super Sampling) and other machine learning.
While the GeForce RTX 3080 (in this example) uses fewer Tensor Cores per SM (4) compared to the GeForce RTX 2080 SUPER’s (8) per SM, the Ampere Tensor Cores with sparsity exceed what Turing could do.
Power Rails
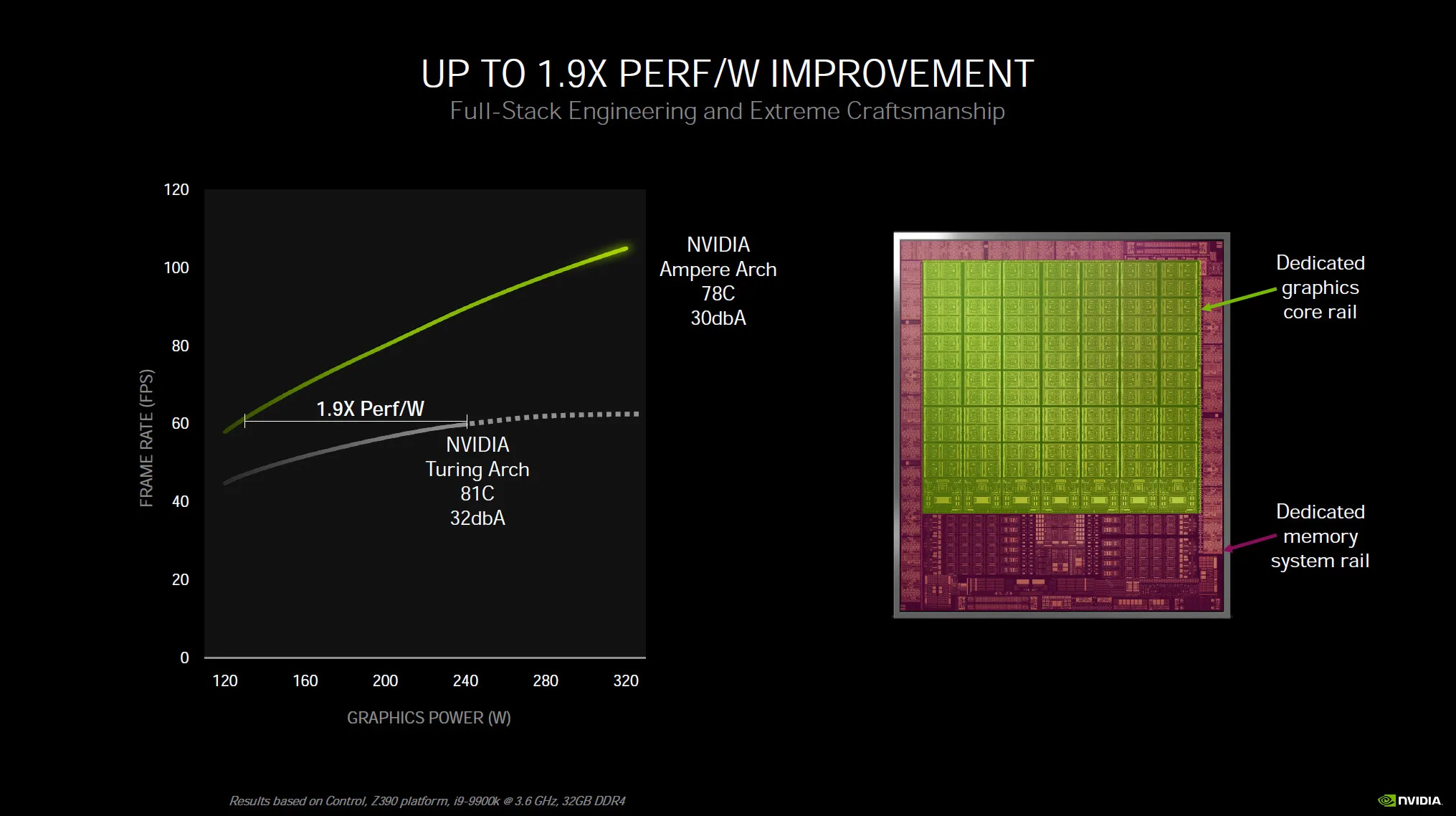
We wanted to show this presentation slide not for the performance per Watt claim, but because of the fact that with Ampere it will have separate power rails. The graphics are on its own power rail, while the memory is on its own rail within the GPU.
GDDR6X
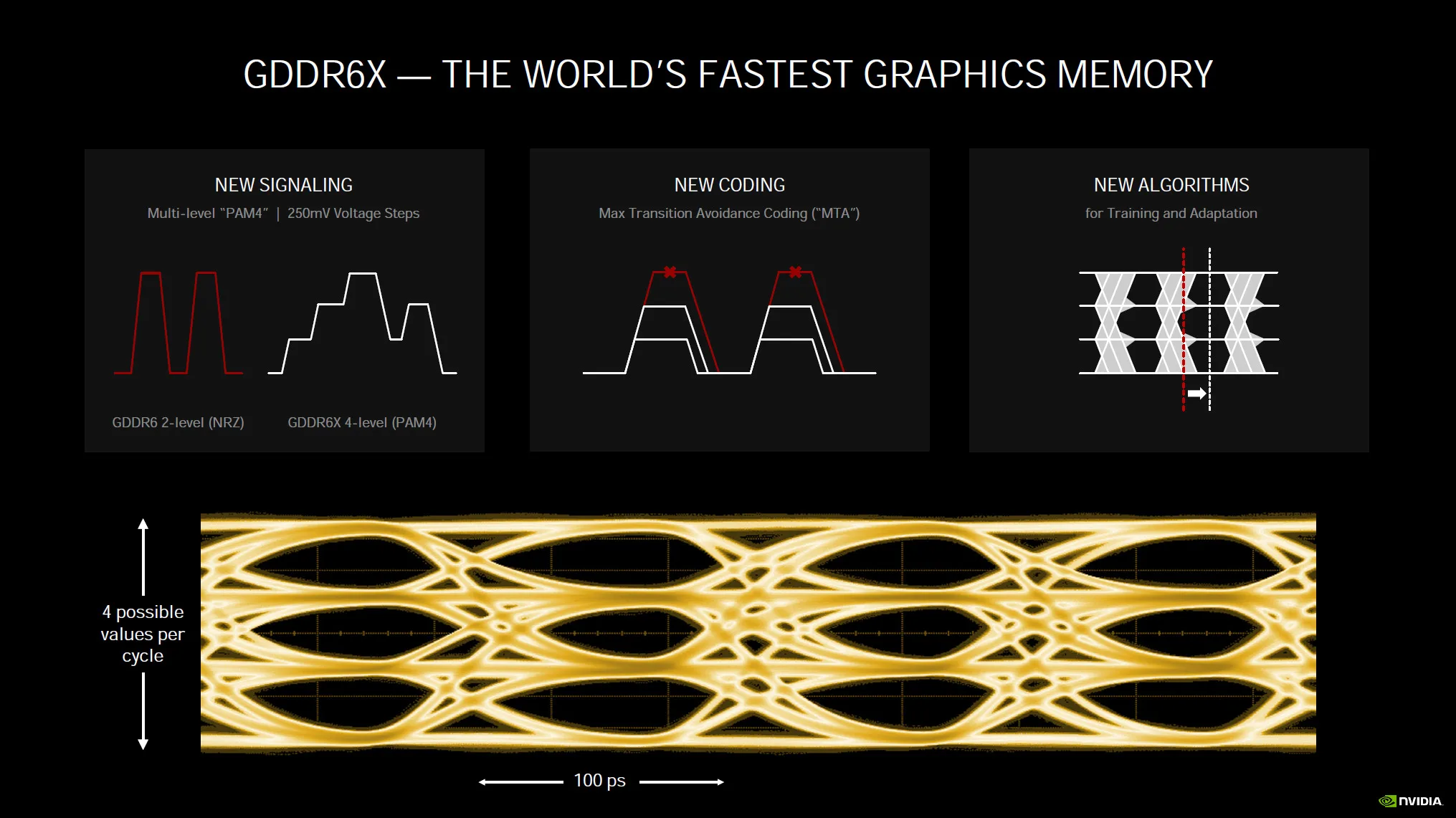
NVIDIA has introduced a new memory technology specifically for the GeForce RTX 3090 and GeForce RTX 3080, GDDR6X. GDDR6X uniquely uses new signaling technology called PAM4. This new signaling technology is forward-looking, and the first time it’s been used on graphics memory. It allows for 4-level stepping in Voltage, combined with new coding called Max Transition Avoidance Coding (MTA) and new algorithms for training and adaptation, memory frequencies can be maintained very high with less interference. Expect to see speeds as high as 19.5GHz (maybe even higher), but at the cost of power. This new memory is power-intensive adding to the total board power.
HDMI 2.1 and AV1


Other enhancements to the Ampere architecture are support for AV1 full hardware decode, which means 8K 60FPS video. These are also the first GPUs to support HDMI 2.1 for 8K at 60Hz or 4K at 120Hz on one cable.
RTX IO

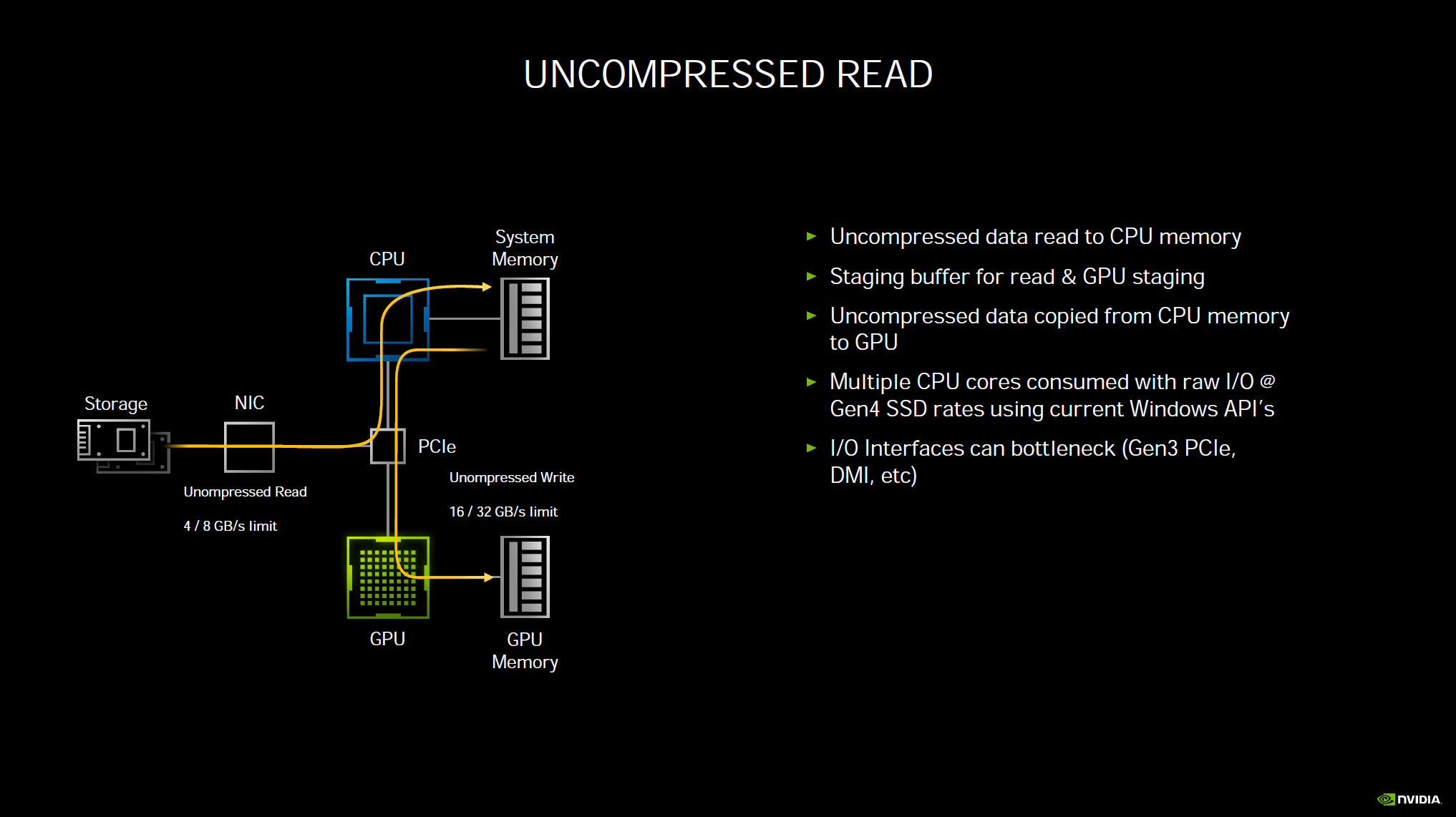
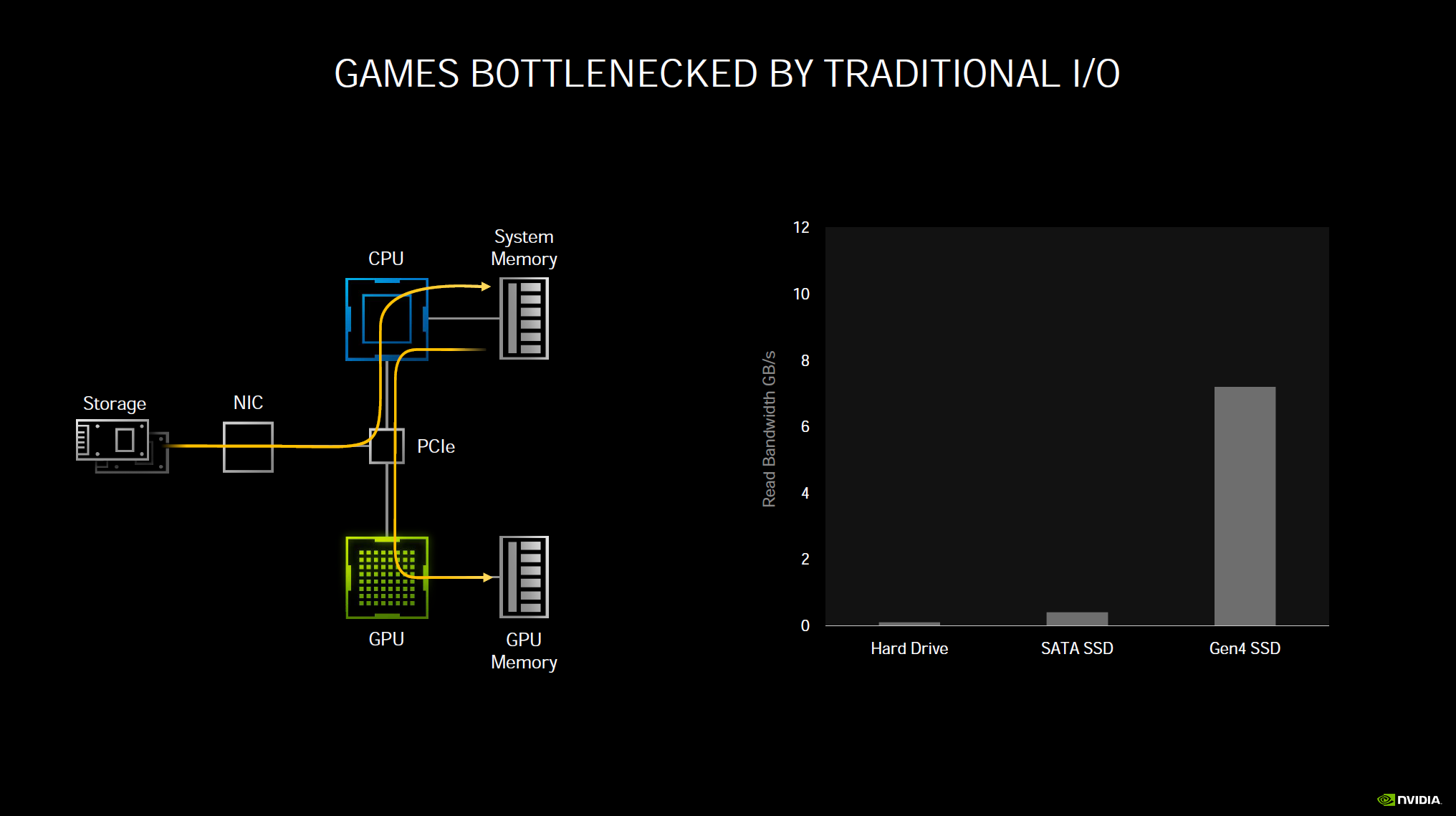
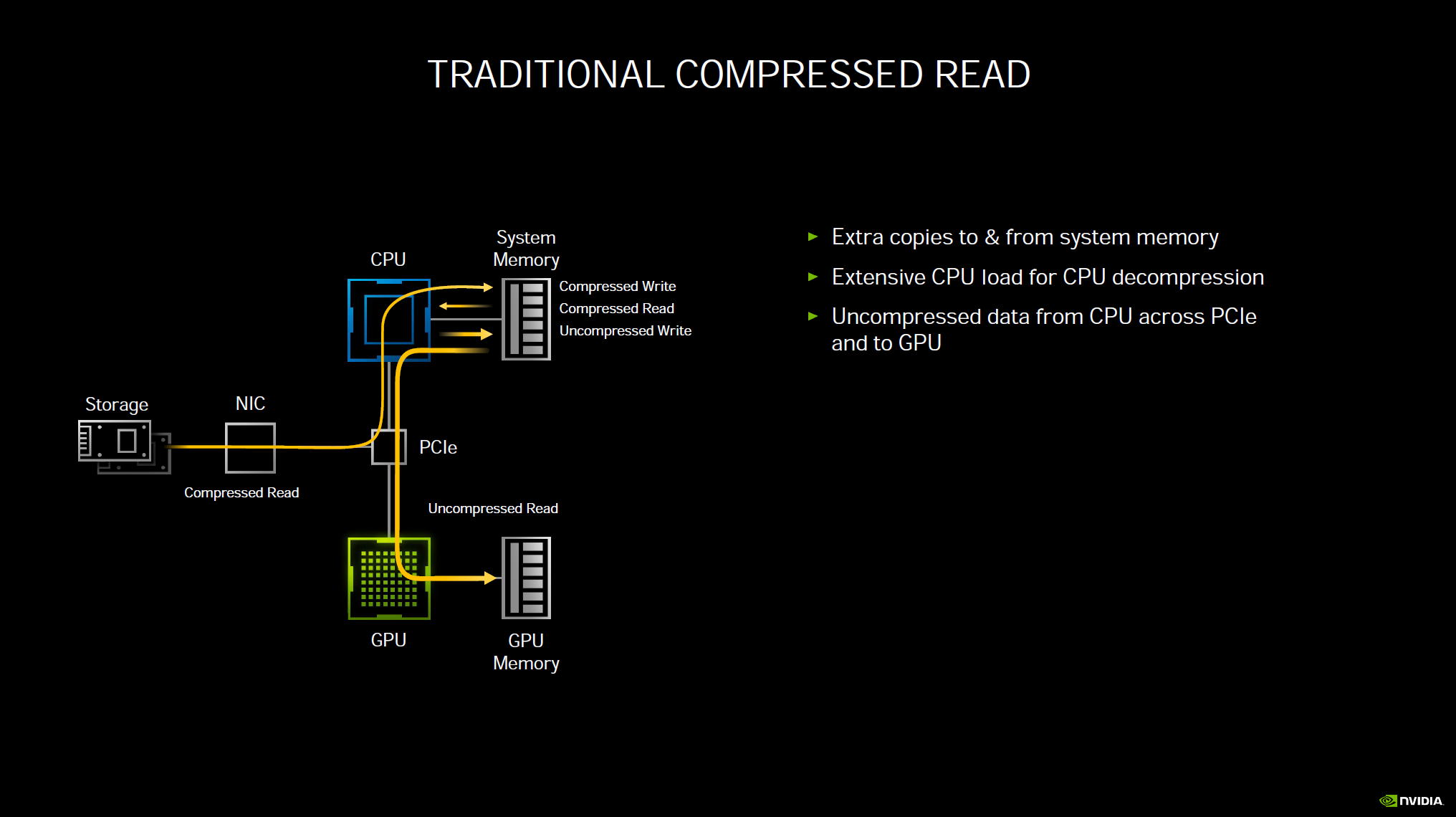
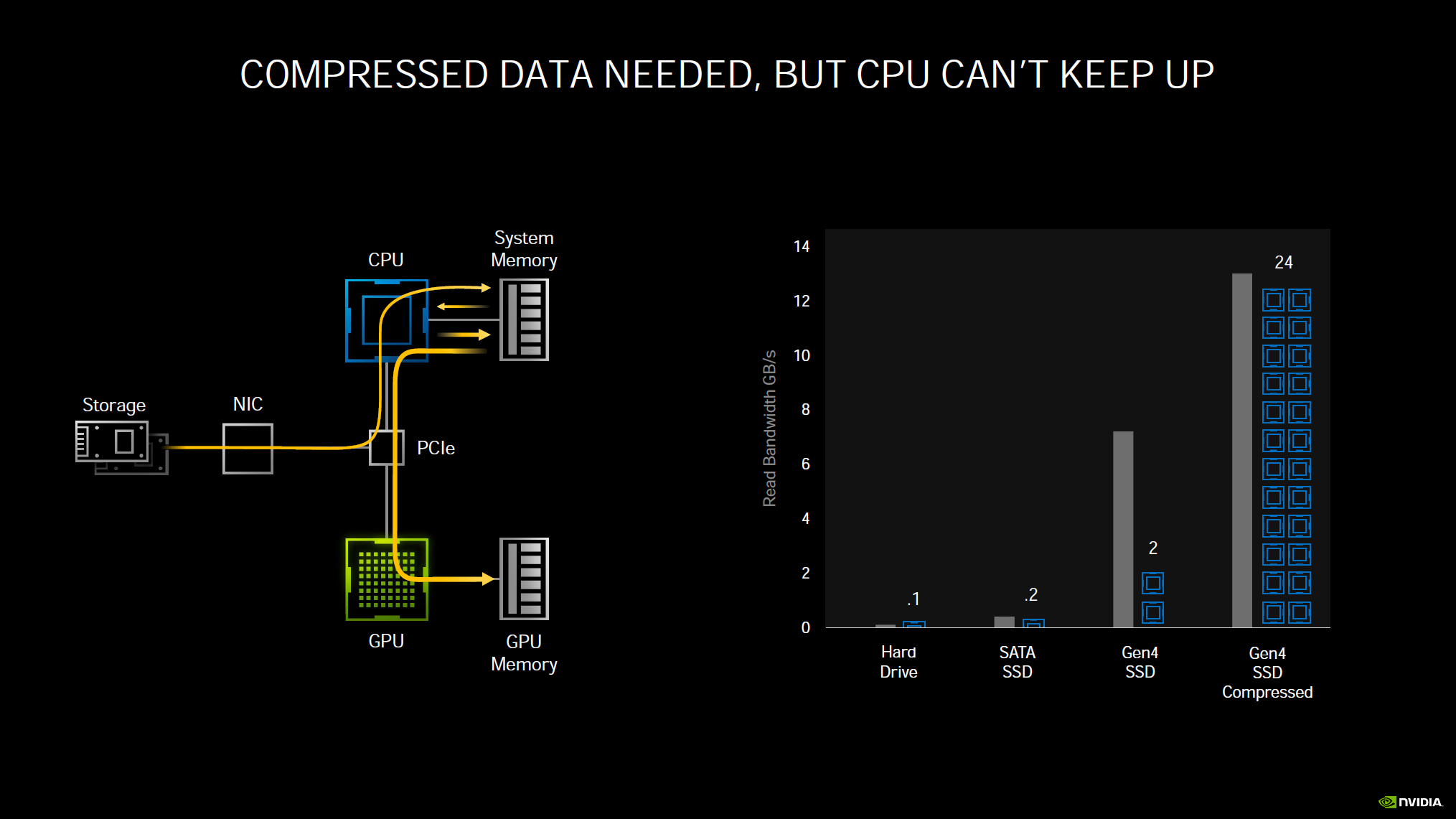
Another new technology NVIDIA announced, which we think will really improve gaming load and streaming is RTX IO. In a traditional uncompressed read, data needs to travel from your storage device, through PCIe to read to CPU and system memory, then it must go out from system memory back on the same bus to the GPU and finally to GPU memory. This consumes a lot of raw CPU processing power and I/O bandwidth. To help, games have been using compressed reads. While this helps a lot, your system is still bottlenecked by having to go through the CPU and system memory to compress and decompress reads and writes, and still travel back to the GPU and GPU memory with heavy CPU load. The CPU cannot keep up with expanding demands and storage device speeds.
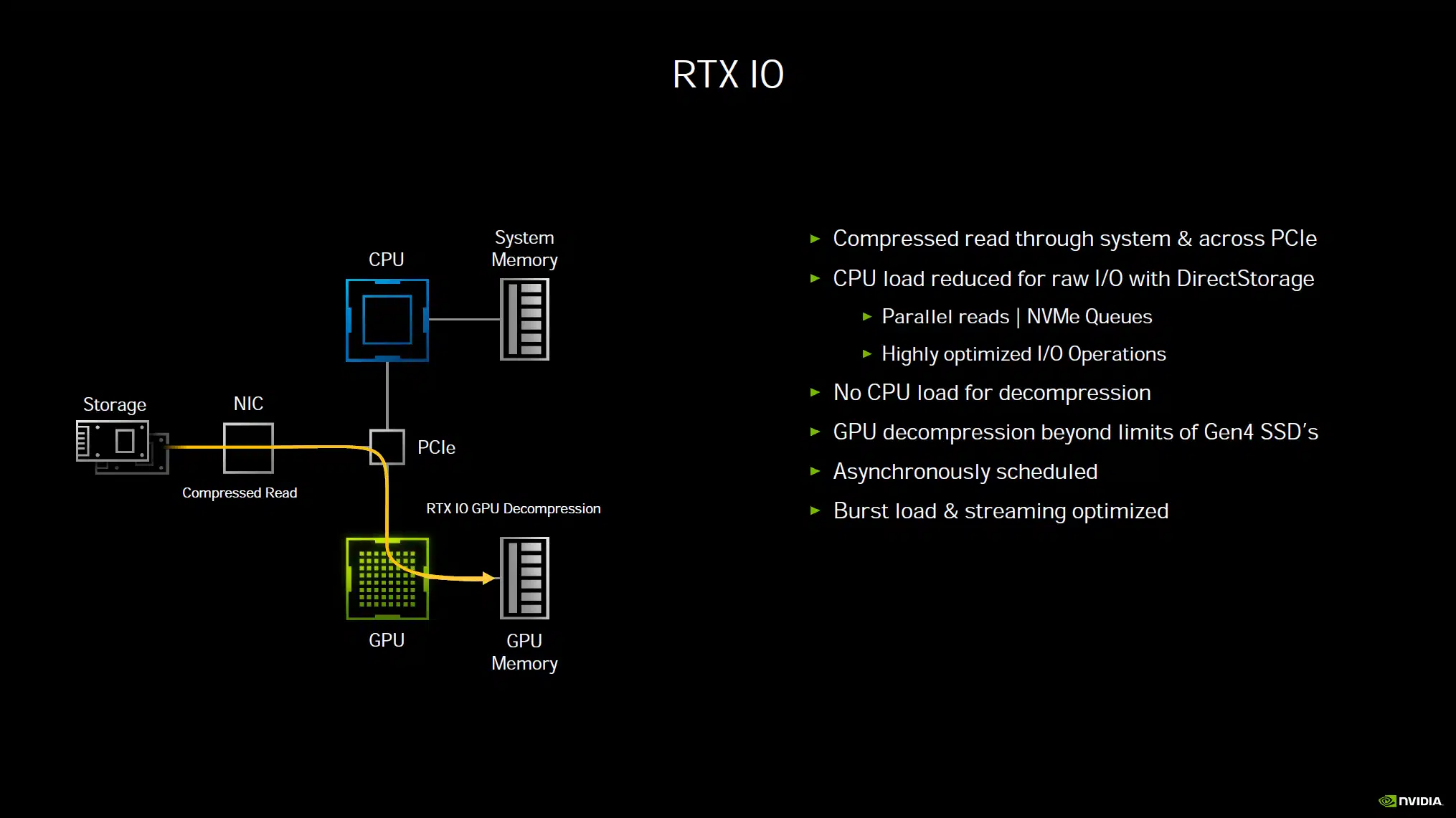
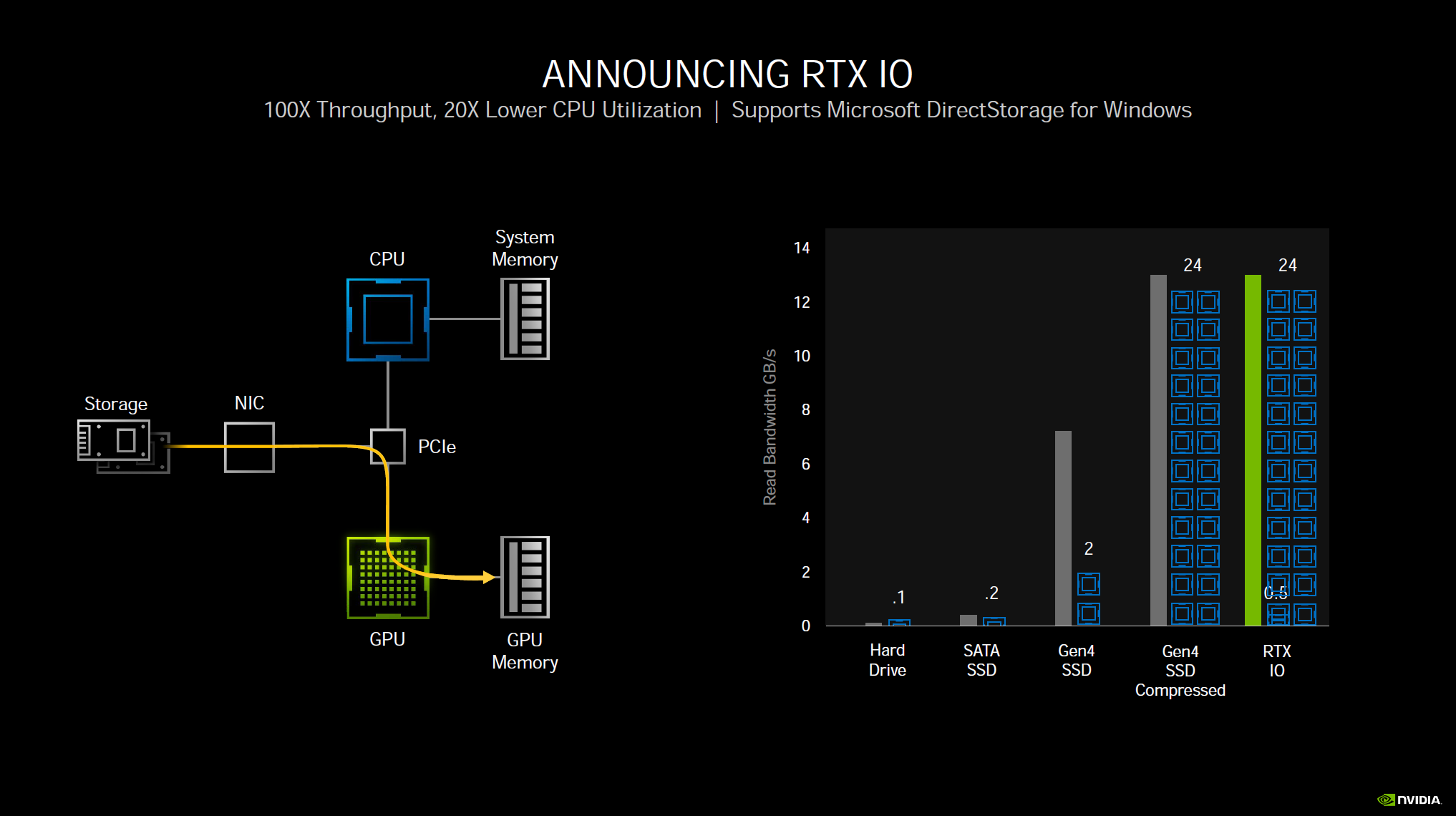
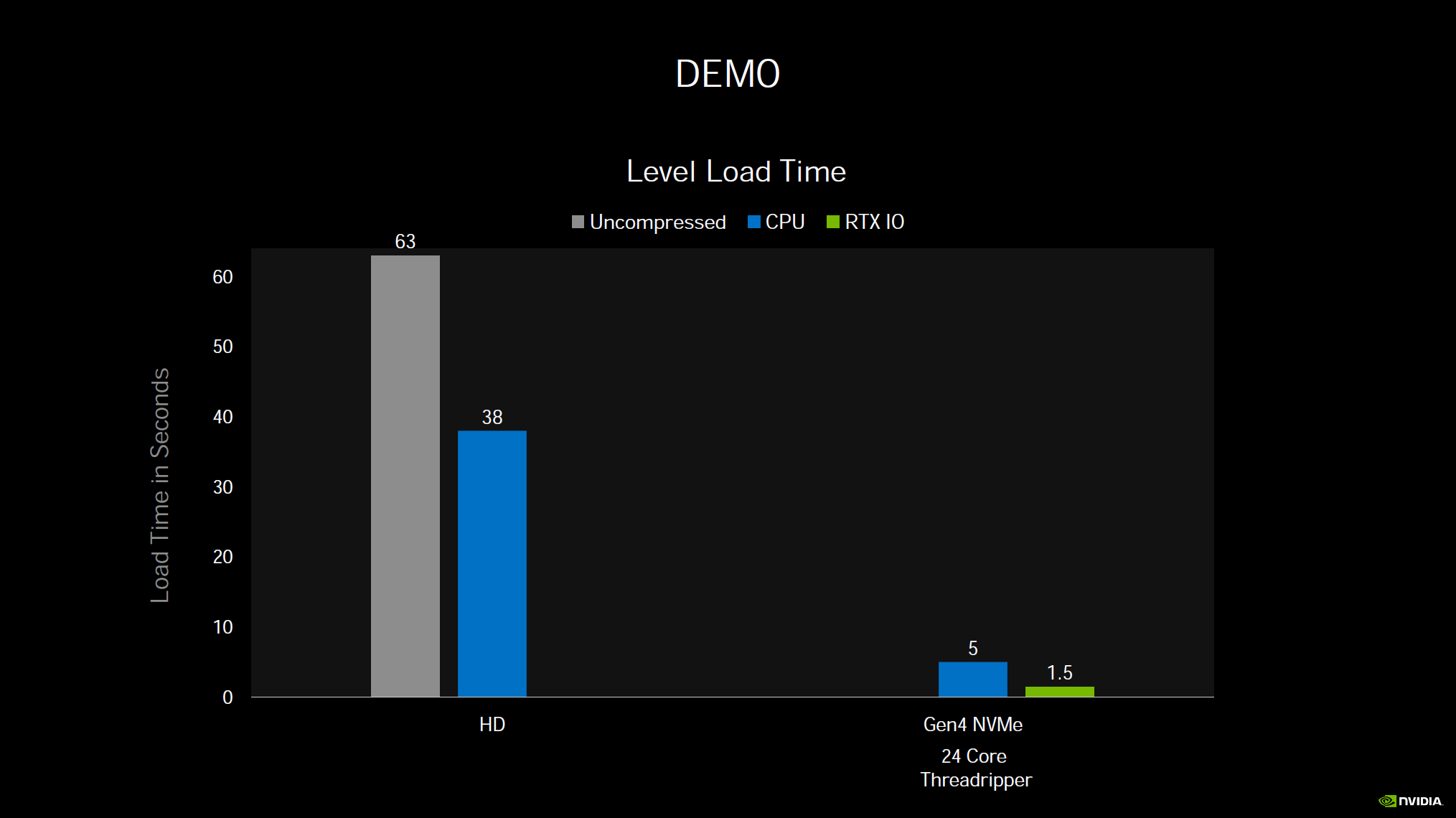
What RTX IO does is to remove these bottlenecks by shifting the load directly to the GPU and GPU memory, removing CPU and system ram from the equation. The GPU can decompress data at tremendous speeds. It only takes half of a GPU core to do what 24 CPU cores can do.
This does not mean games can use your SSD as “RAM” or “VRAM” storage, like the PlayStation 5. It simply means the decompressing of data can be offloaded to the GPU and sent directly to VRAM bypassing bottlenecks of CPU burden and I/O. NVIDIA states that this will not take away from your GPU performance accelerating games, as the GPU takes very little resources to do this, it can do it very quickly, unlike the CPU. It will alleviate burdens in the system, not add to them.
Now, this technology is a bit down the road, as we wait for DirectStorage to come to Windows next year from Microsoft. NVIDIA RTX I/O plugs into the DirectStorage API. The games must support it. However, this technology could really be a big game-changer for PC gaming loading and streaming and NVIDIA seems to be at the forefront of this technology.
NVIDIA Reflex





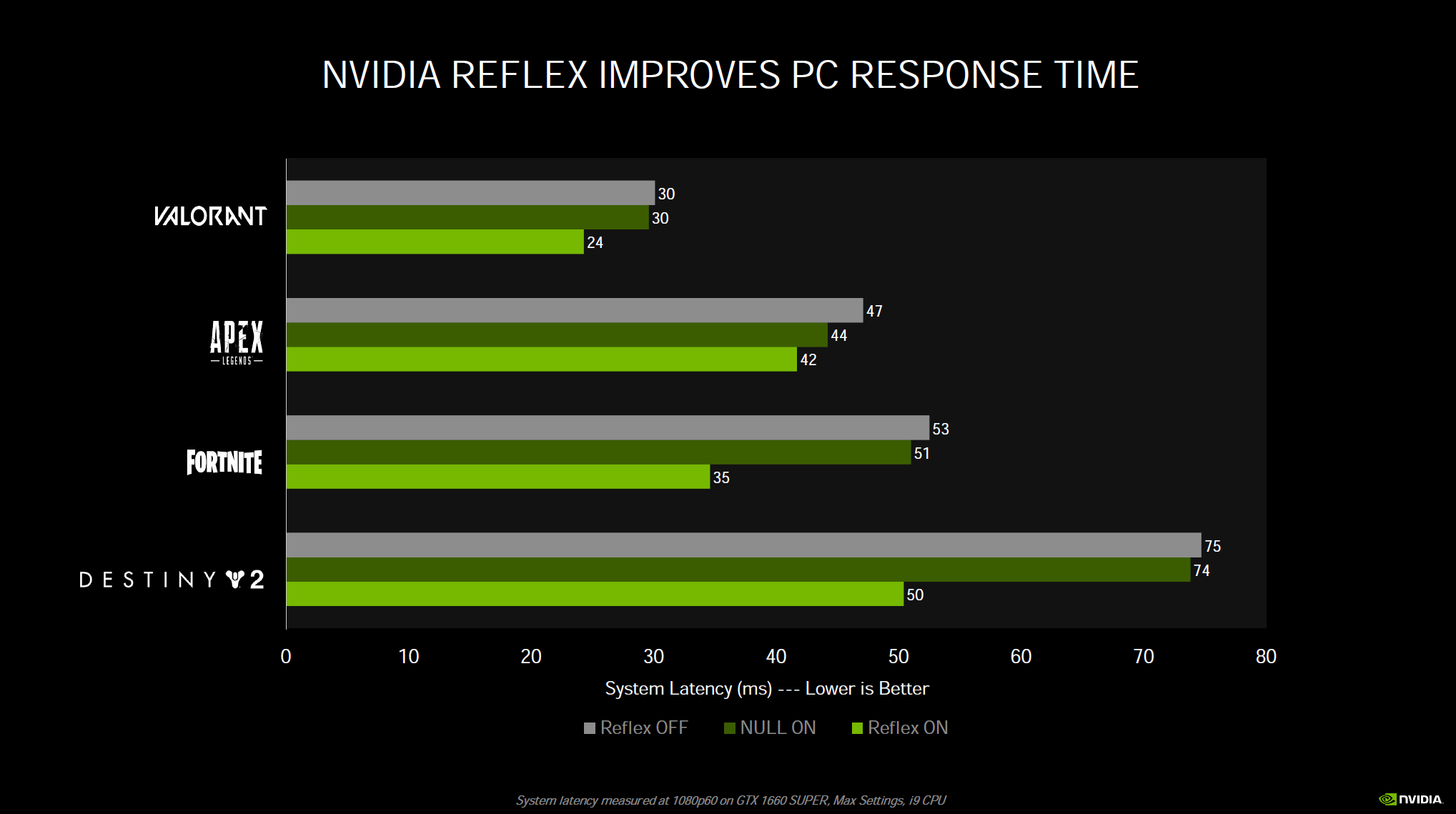
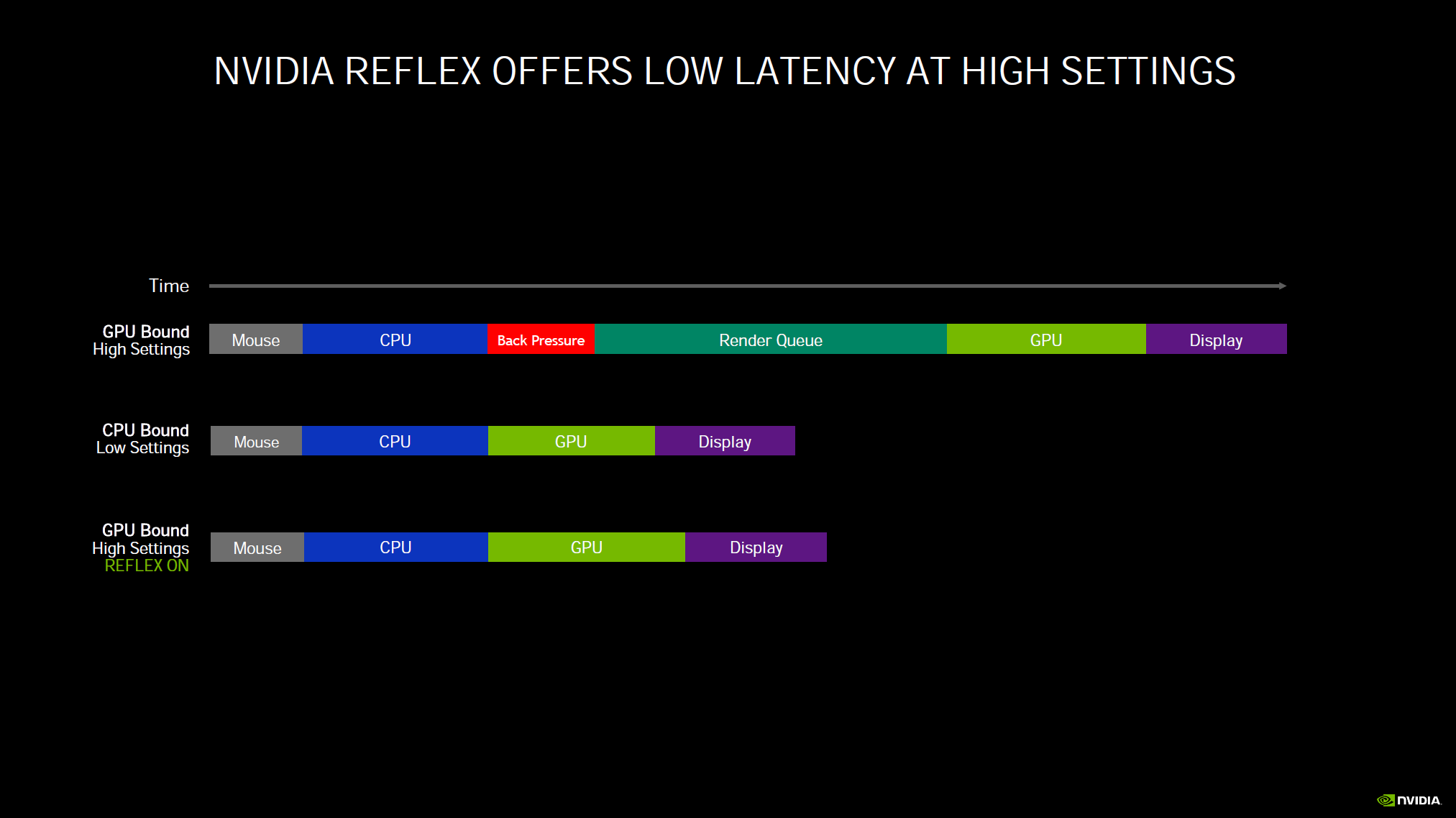
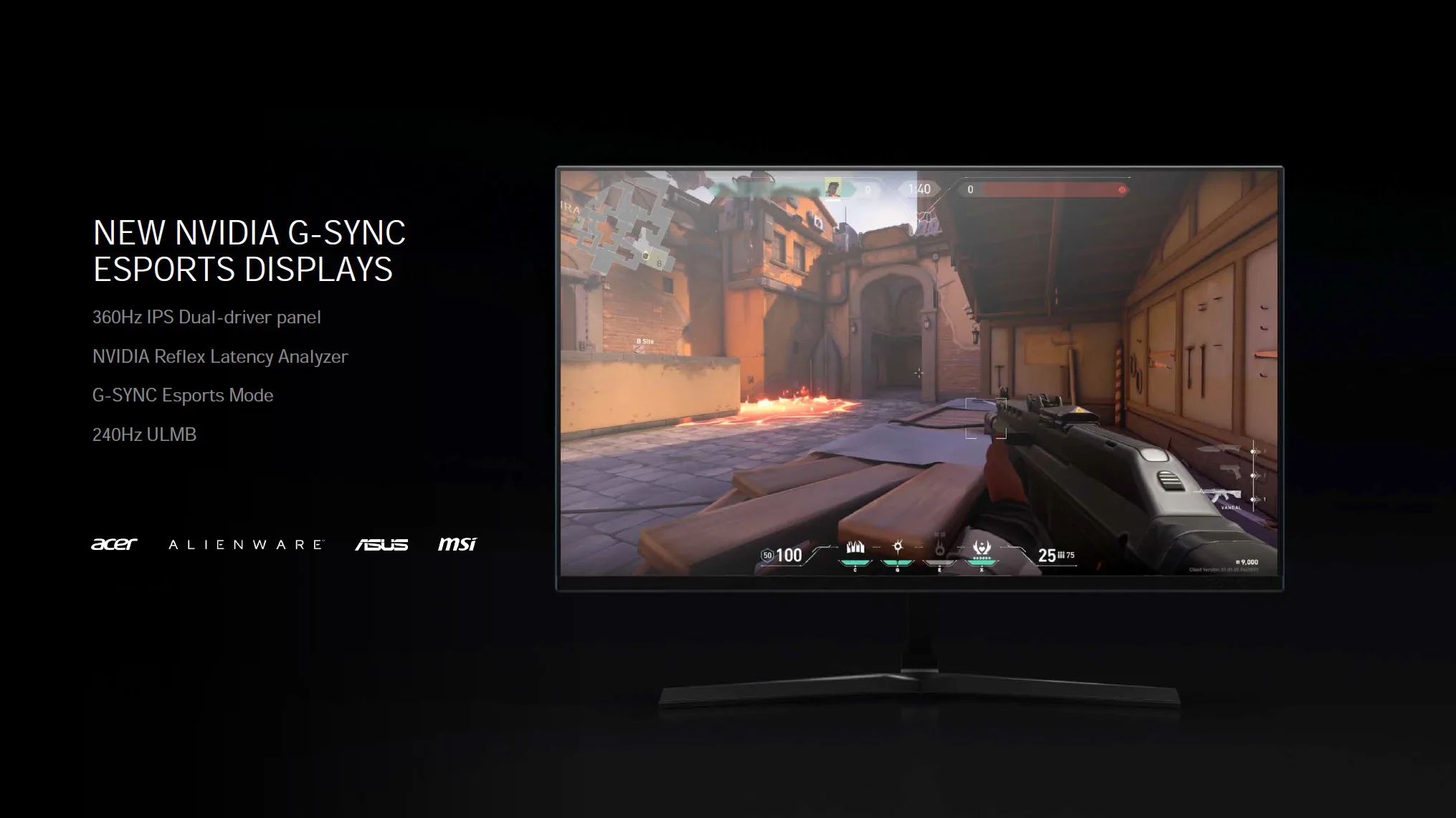
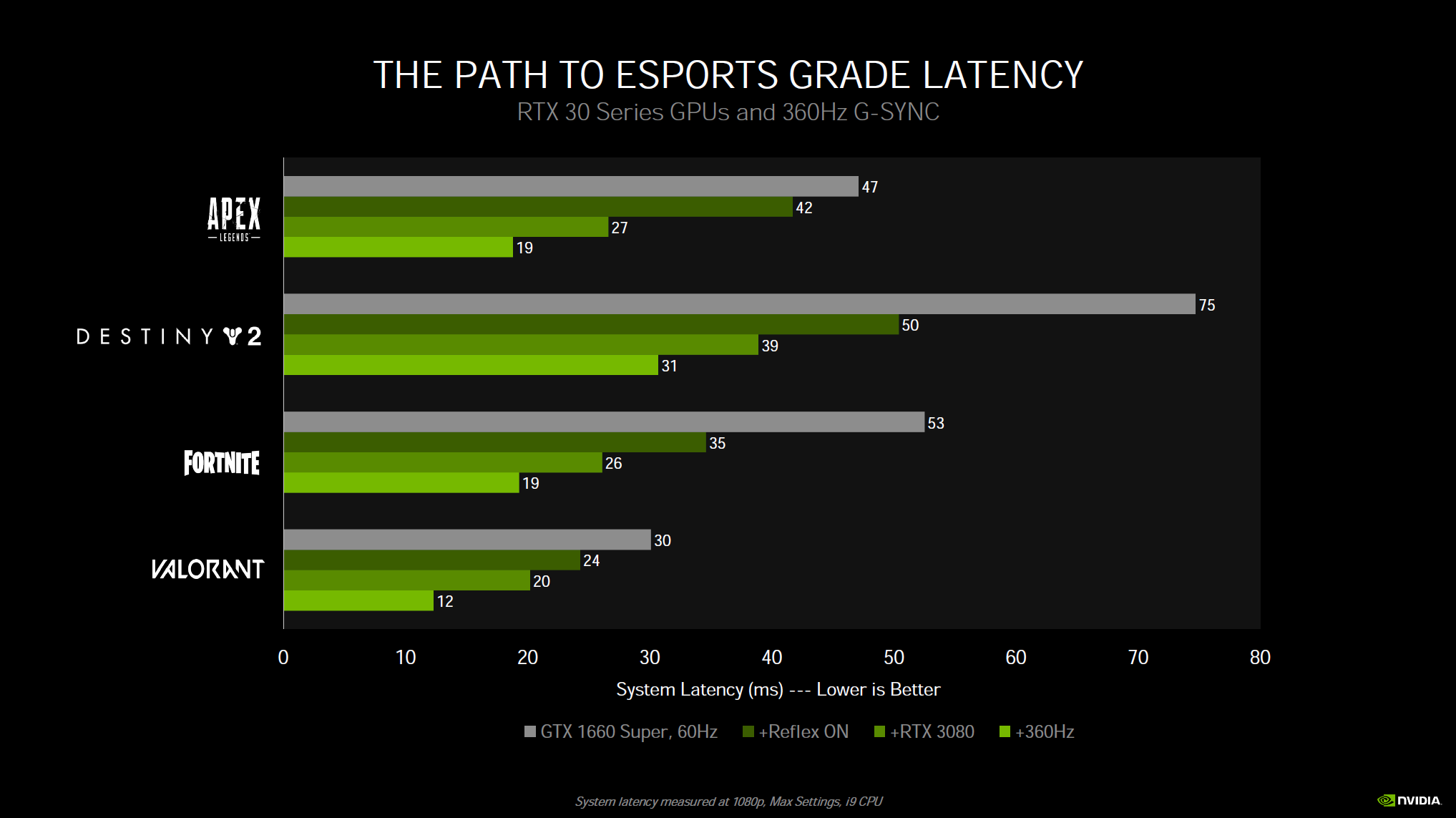
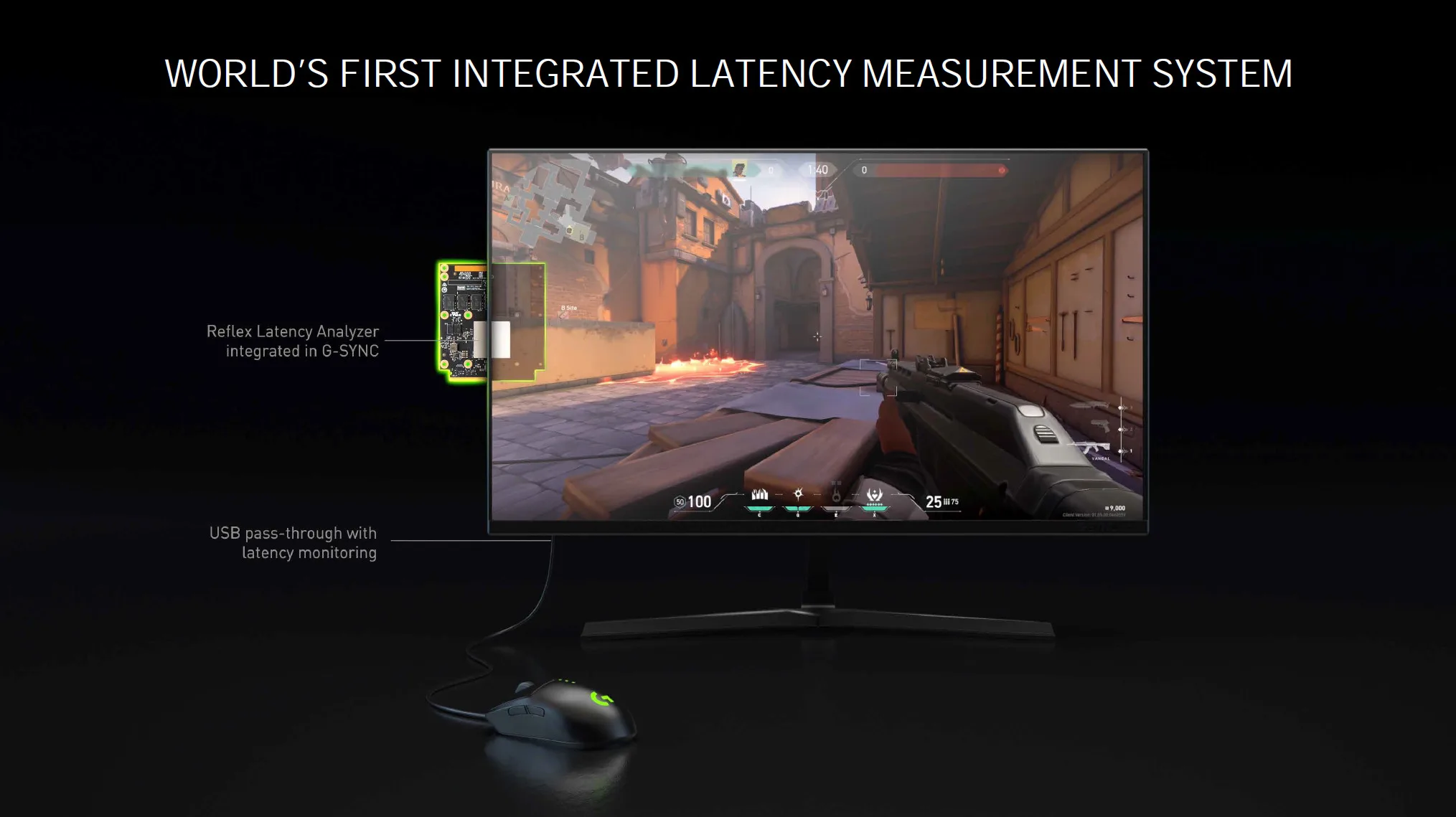
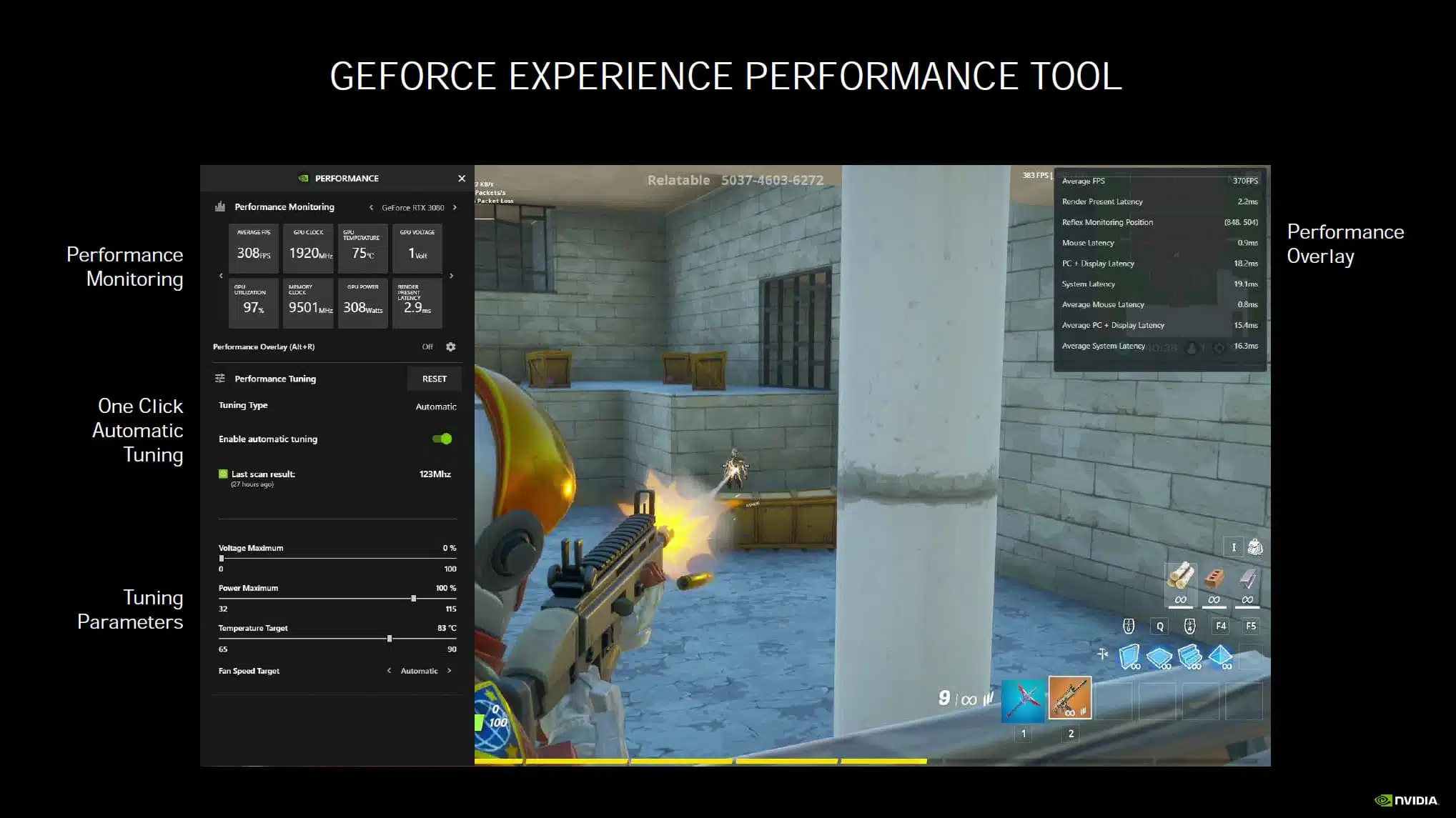
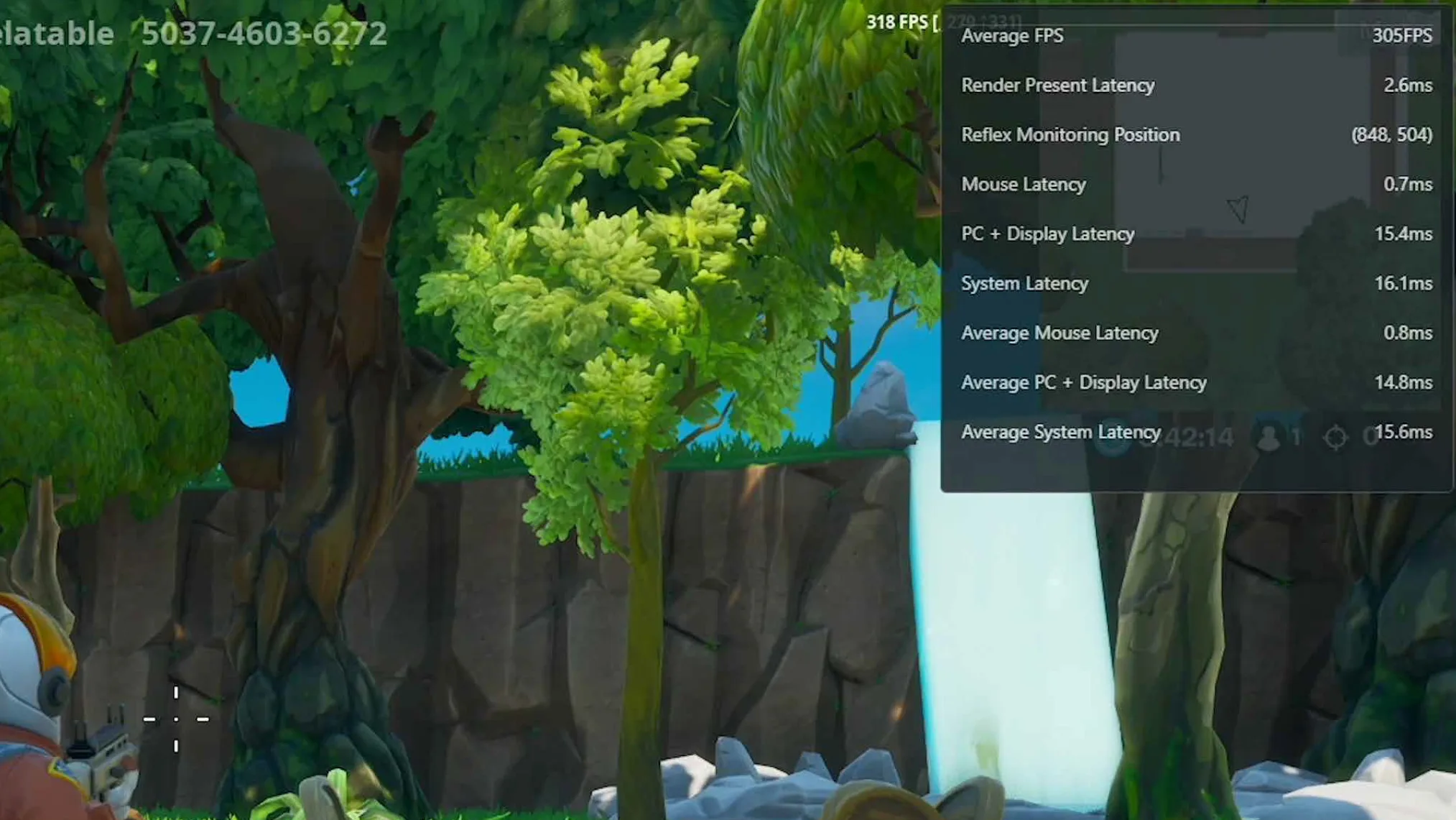

Finally, NVIDIA is also introducing NVIDIA Reflex, a technology to reduce input lag while gaming. If you want to reduce latency games will have an option and you just simply turn it on in the games that support it. One area where this technology is really going to start taking shape and showing the most benefit is on displays with insanely high refresh rates, like the new 360Hz panels coming out. In addition, there will be hardware analyzing support built into GSYNC monitors that lets you measure latency in a new and unique way. With Reflex Latency Analyzer you actually plug your mouse into the monitor and monitor latency in ways never done before. But the actual Reflex Low Latency SDK technology is software and enabled in-game on supported games, and you connect your mouse normally as you would to the computer.
Summary
Therefore, at the end of the day, there are three primary improvements in Ampere over Turing to improve performance. The “shaders” or CUDA Cores have been improved by doubling FP32 operations inside the SM. Ray Tracing Cores have been improved by doubling the triangle intersection rates, allowing concurrent Ray Tracing and Shader ops, and removing Motion Blur as a bottleneck. Tensor Cores have been improved by doubling the throughput of sparse matrices and removing less important DNN weights.
Overall, there are also more RT Cores and more Tensor Cores on each GPU as well. It seems NVIDIA is doubling-down on Ray Tracing and AI performance, such as DLSS with Ampere. Ampere is really shaping up to be a floating-point powerhouse.